This implements arm, armeb, thumb, thumbeb PLT entries parsing support
in ELF for llvm-objdump.
Implementation is similar to AArch64MCInstrAnalysis::findPltEntries. PLT
entry signatures are based on LLD code for PLT generation
(ARM::writePlt).
llvm-objdump tests are produced from lld/test/ELF/arm-plt-reloc.s,
lld/test/ELF/armv8-thumb-plt-reloc.s.
DenseSet, SmallPtrSet, SmallSet, SetVector, and StringSet recently
gained C++23-style insert_range. This patch replaces:
Dest.insert(Src.begin(), Src.end());
with:
Dest.insert_range(Src);
This patch does not touch custom begin like succ_begin for now.
Currently, `DIContext::getLineInfoForAddress` and
`DIContext::getLineInfoForDataAddress` returns empty DILineInfo when the
debug info is missing for the given address. This is not differentiable
with the case when debug info is found for the given address but the
debug info is default value (filename:linenum is <invalid>:0).
This change wraps the return types of `DIContext::getLineInfoForAddress`
and `DIContext::getLineInfoForDataAddress` with `std::optional`.
and fix crash when vd_aux is invalid (#86611).
vd_version, vd_flags, vd_ndx, and vd_cnt in Elf{32,64}_Verdef are
16-bit. Change VerDef to use uint16_t instead.
vda_name specifies a NUL-terminated string. Update getVersionDefinitions
to remove some `.c_str()`.
Pull Request: https://github.com/llvm/llvm-project/pull/128434
The dynamic string table used by the dynamic section is referenced by
the sh_link field of that section, so we should use that directly,
rather than going via the dynamic symbol table.
More info:
https://github.com/llvm/llvm-project/pull/125679#discussion_r1961333454
Signed-off-by: Ruoyu Qiu <cabbaken@outlook.com>
Now that we have a dedicated abstraction for string tables, switch the
option parser library's string table over to it rather than using a raw
`const char*`. Also try to use the `StringTable::Offset` type rather
than a raw `unsigned` where we can to avoid accidental increments or
other issues.
This is based on review feedback for the initial switch of options to a
string table. Happy to tweak or adjust if desired here.
Adds support to objdump and readobj for reading the `UOP_Epilog` entries
of Windows x64 unwind v2.
`UOP_Epilog` has a weird format:
The first `UOP_Epilog` in the unwind data is the "header":
* The least-significant bit of `OpInfo` is the "At End" flag, which
signifies that there is an epilog at the very end of the associated
function.
* `CodeOffset` is the length each epilog described by the current unwind
information (all epilogs have the same length).
Any subsequent `UOP_Epilog` represents another epilog for the current
function, where `OpInfo` and `CodeOffset` are combined to a 12-bit value
which is the offset of the beginning of the epilog from the end of the
current function. If the offset is 0, then this entry is actually
padding and can be ignored.
Apologies for the large change, I looked for ways to break this up and
all of the ones I saw added real complexity. This change focuses on the
option's prefixed names and the array of prefixes. These are present in
every option and the dominant source of dynamic relocations for PIE or
PIC users of LLVM and Clang tooling. In some cases, 100s or 1000s of
them for the Clang driver which has a huge number of options.
This PR addresses this by building a string table and a prefixes table
that can be referenced with indices rather than pointers that require
dynamic relocations. This removes almost 7k dynmaic relocations from the
`clang` binary, roughly 8% of the remaining dynmaic relocations outside
of vtables. For busy-boxing use cases where many different option tables
are linked into the same binary, the savings add up a bit more.
The string table is a straightforward mechanism, but the prefixes
required some subtlety. They are encoded in a Pascal-string fashion with
a size followed by a sequence of offsets. This works relatively well for
the small realistic prefixes arrays in use.
Lots of code has to change in order to land this though: both all the
option library code has to be updated to use the string table and
prefixes table, and all the users of the options library have to be
updated to correctly instantiate the objects.
Some follow-up patches in the works to provide an abstraction for this
style of code, and to start using the same technique for some of the
other strings here now that the infrastructure is in place.
Swap `!DisassembleZeroes` and `if (DumpARMELFData)` conditions so that
in the false DisassembleZeroes case (default), `...` will be printed for
long consecutive zeroes, even when a data mapping symbol is active.
This is especially useful for certain lld tests that insert a huge
padding within a code section. Without `...` the output will be huge.
Pull Request: https://github.com/llvm/llvm-project/pull/109553
In a mach_header, the cpusubtype is a 32-bit field, but it's split in 2
subfields:
- the low 24 bits containing the cpu subtype proper, (e.g.,
CPU_SUBTYPE_ARM64E 2)
- the high 8 bits containing a capability field used for additional
feature flags.
Notably, it's only the subtype subfield that participates in fat file
slice discrimination: the caps are ignored.
arm64e uses the caps subfield to encode a ptrauth ABI version:
- 0x80 (CPU_SUBTYPE_PTRAUTH_ABI) denotes a versioned binary
- 0x40 denotes a kernel-ABI binary
- 0x00-0x0F holds the ptrauth ABI version
This teaches the basic obj tools to decode that (or ignore it when
unneeded).
It also teaches the MachO writer to default to emitting versioned
binaries, but with a version of 0 (and without the kernel ABI flag).
Modern arm64e requires versioned binaries: a binary with 0x00 caps in
cpusubtype is now rejected by the linker and everything after. We can
live without the sophistication of specifying the version and kernel ABI
for now.
Co-authored-by: Francis Visoiu Mistrih <francisvm@apple.com>
The section field has been repurposed for some STAB symbol types, and if
we blindly look it up we'll produce an error and terminate. Logic
already existed
Existing stabs test had a section that was in range. Unfortunately I
don't know of an easy way to produce stabs entries in LLVM (I thought
they died in the 90s until this came up) so I just binary-edited it to
cause a failure on existing llvm-objdump.
Enable local labels computation for BPF disassembly when
`--symbolize-operands` option is specified.
This relies on `MCInstrAnalysis::evaluateBranch()` method, which is
already defined in `BPFMCInstrAnalysis::evaluateBranch`.
After this change the assembly code below:
if r1 > 42 goto +1
r1 -= 10
...
Would be printed as:
if r1 > 42 goto +1 <L0>
r1 -= 10
<L0>:
...
(when `--symbolize-operands` option is set).
See https://reviews.llvm.org/D84191 for the main part of the
`--symbolize-operands` implementation logic.
Extract the llvm-readelf decoder to `decodeCrel` (#91280) and reuse it
for llvm-objdump.
Because the section representation of LLVMObject (`SectionRef`) is
64-bit, insufficient to hold all decoder states, `section_rel_begin` is
modified to decode CREL eagerly and hold the decoded relocations inside
ELFObjectFile<ELFT>.
The test is adapted from llvm/test/tools/llvm-readobj/ELF/crel.test.
Pull Request: https://github.com/llvm/llvm-project/pull/97382
I'm planning to remove StringRef::equals in favor of
StringRef::operator==.
- StringRef::operator==/!= outnumber StringRef::equals by a factor of
70 under llvm/ in terms of their usage.
- The elimination of StringRef::equals brings StringRef closer to
std::string_view, which has operator== but not equals.
- S == "foo" is more readable than S.equals("foo"), especially for
!Long.Expression.equals("str") vs Long.Expression != "str".
These mostly are checking for various reserved bits being set. The diagnostics
for gpu-dependent reserved bits have a bit more context since they seem like the
most likely ones to be observed in practice.
This commit also improves the error handling mechanism for
MCDisassembler::onSymbolStart(). Previously it had a comment stream parameter
that was just being ignored by llvm-objdump, now it returns errors using
Expected<T>.
When reading the dynamic string table, llvm-objdump used to crash if the
ELF was malformed, due to an erroneous consumption of error status.
Instead, propogate the error status to the caller, fixing the crash, and
printing a warning.
The color methods in formatted_raw_ostream were forwarding directly to
the underlying stream without considering existing buffered output. This
would cause incorrect colored output for buffered uses of
formatted_raw_ostream.
Fix this issue by applying the color to the formatted_raw_ostream itself
and temporarily disabling scanning of any color related output so as not
to affect the position tracking.
This fix means that workarounds that forced formatted_raw_ostream
buffering to be disabled can be removed. In the case of llvm-objdump,
this can improve disassembly performance when redirecting to a file by
more than an order of magnitude on both Windows and Linux. This
improvement restores the disassembly performance when redirecting to a
file to a level similar to before color support was added.
`macho-relative-method-lists.test` is failing on little endian
platforms, when matching 'name'.
```
CHK32-NEXT: name 0x144 (0x{{[0-9a-f]*}}) instance_method_00
next:10'0 X error: no match found
18: name 0x144 (0x7ac)
```
This seems like the obvious fix.
Co-authored-by: Alex B <alexborcan@meta.com>
For Mach-O, ld64 supports the -fobjc-relative-method-lists flag which
changes the format in which method lists are generated. The format uses
delta encoding vs the original direct-pointer encoding.
This change adds support to llvm-objdump and llvm-otool for
decoding/dumping of method lists in the delta format. Previously, if a
binary with this information format was passed to the tooling, it would
output invalid information, trying to parse the delta lists as pointer
lists.
After this change, the tooling will output correct information if a
binary in this format is encountered.
The output format is closest feasible match to XCode 15.1's otool
output. Tests are included for both 32bit and 64bit binaries.
The code style was matched as close as possible to existing
implementation of parsing non-delta method lists.
Diff between llvm-objdump and XCode 15.1 otool:

Note: This is a retry of this PR:
https://github.com/llvm/llvm-project/pull/84250
On the original PR, the armv7+armv8 builds were failing due to absolute
offsets being different.
Co-authored-by: Alex B <alexborcan@meta.com>
For Mach-O, ld64 supports the `-fobjc-relative-method-lists` flag which
changes the format in which method lists are generated. The format uses
delta encoding vs the original direct-pointer encoding.
This change adds support to `llvm-objdump` and `llvm-otool` for
decoding/dumping of method lists in the delta format. Previously, if a
binary with this information format was passed to the tooling, it would
output invalid information, trying to parse the delta lists as pointer
lists.
After this change, the tooling will output correct information if a
binary in this format is encountered.
The output format is closest feasible match to XCode 15.1's otool
output. Tests are included for both 32bit and 64bit binaries.
The code style was matched as close as possible to existing
implementation of parsing non-delta method lists.
Diff between llvm-objdump and XCode 15.1 otool:
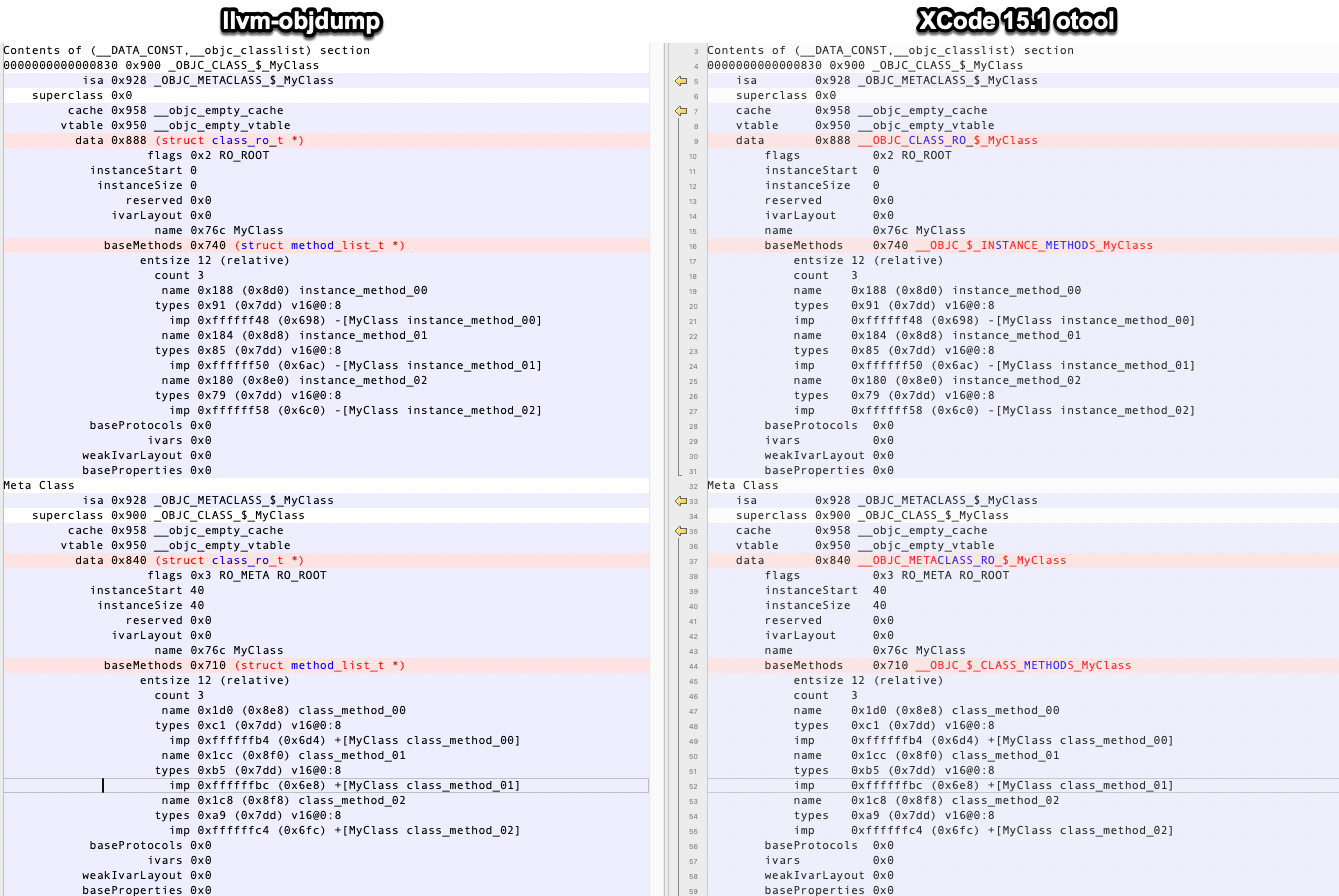
---------
Co-authored-by: Alex B <alexborcan@meta.com>
Primary change is to add a flag `--pretty-pgo-analysis-map` to
llvm-readobj and llvm-objdump that prints block frequencies and branch
probabilities in the same manner as BFI and BPI respectively. This can
be helpful if you are manually inspecting the outputs from the tools.
In order to print, I moved the `printBlockFreqImpl` function from
Analysis to Support and renamed it to `printRelativeBlockFreq`.
nm already prints sizes for data symbols. Do that for function symbols
too, and update objdump to also print size information.
Implements item 3 from https://github.com/llvm/llvm-project/issues/76107
Wasm has no unified virtual memory space as other object formats and
architectures do, so previously WasmObjectFile reported 0 for all
section addresses, and until 428cf71ff used section offsets for function
symbols. Now we use file offsets for function symbols, and this change
switches section addresses to do the same (in linked files). The main
result of this is that objdump now reports VMAs in section listings, and
also uses file offets rather than section offsets when disassembling
linked binaries (matching the behavior of other disassemblers and stack
traces produced by browwsers). To make this work, this PR also updates
objdump's generation of synthetics fallback symbols to match lib/Object
and also correctly plumbs symbol types for regular and dummy symbols
through to the backend to avoid needing special knowledge of address 0.
This also paves the way for generating symbols from name sections rather
than symbol tables or imports (see #76107) by allowing the
disassembler's synthetic fallback symbols match the name-section
generated symbols (in a followup PR).
Today `-split-machine-functions` and `-fbasic-block-sections={all,list}`
cannot be combined with `-basic-block-sections=labels` (the labels
option will be ignored).
The inconsistency comes from the way basic block address map -- the
underlying mechanism for basic block labels -- encodes basic block
addresses
(https://lists.llvm.org/pipermail/llvm-dev/2020-July/143512.html).
Specifically, basic block offsets are computed relative to the function
begin symbol. This relies on functions being contiguous which is not the
case for MFS and basic block section binaries. This means Propeller
cannot use binary profiles collected from these binaries, which limits
the applicability of Propeller for iterative optimization.
To make the `SHT_LLVM_BB_ADDR_MAP` feature work with basic block section
binaries, we propose modifying the encoding of this section as follows.
First let us review the current encoding which emits the address of each
function and its number of basic blocks, followed by basic block entries
for each basic block.
| | |
|--|--|
| Address of the function | Function Address |
| Number of basic blocks in this function | NumBlocks |
| BB entry 1
| BB entry 2
| ...
| BB entry #NumBlocks
To make this work for basic block sections, we treat each basic block
section similar to a function, except that basic block sections of the
same function must be encapsulated in the same structure so we can map
all of them to their single function.
We modify the encoding to first emit the number of basic block sections
(BB ranges) in the function. Then we emit the address map of each basic
block section section as before: the base address of the section, its
number of blocks, and BB entries for its basic block. The first section
in the BB address map is always the function entry section.
| | |
|--|--|
| Number of sections for this function | NumBBRanges |
| Section 1 begin address | BaseAddress[1] |
| Number of basic blocks in section 1 | NumBlocks[1] |
| BB entries for Section 1
|..................|
| Section #NumBBRanges begin address | BaseAddress[NumBBRanges] |
| Number of basic blocks in section #NumBBRanges |
NumBlocks[NumBBRanges] |
| BB entries for Section #NumBBRanges
The encoding of basic block entries remains as before with the minor
change that each basic block offset is now computed relative to the
begin symbol of its containing BB section.
This patch adds a new boolean codegen option `-basic-block-address-map`.
Correspondingly, the front-end flag `-fbasic-block-address-map` and LLD
flag `--lto-basic-block-address-map` are introduced.
Analogously, we add a new TargetOption field `BBAddrMap`. This means BB
address maps are either generated for all functions in the compiling
unit, or for none (depending on `TargetOptions::BBAddrMap`).
This patch keeps the functionality of the old
`-fbasic-block-sections=labels` option but does not remove it. A
subsequent patch will remove the obsolete option.
We refactor the `BasicBlockSections` pass by separating the BB address
map and BB sections handing to their own functions (named
`handleBBAddrMap` and `handleBBSections`). `handleBBSections` renumbers
basic blocks and places them in their assigned sections.
`handleBBAddrMap` is invoked after `handleBBSections` (if requested) and
only renumbers the blocks.
- New tests added:
- Two tests basic-block-address-map-with-basic-block-sections.ll and
basic-block-address-map-with-mfs.ll to exercise the combination of
`-basic-block-address-map` with `-basic-block-sections=list` and
'-split-machine-functions`.
- A driver sanity test for the `-fbasic-block-address-map` option
(basic-block-address-map.c).
- An LLD test for testing the `--lto-basic-block-address-map` option.
This reuses the LLVM IR from `lld/test/ELF/lto/basic-block-sections.ll`.
- Renamed and modified the two existing codegen tests for basic block
address map (`basic-block-sections-labels-functions-sections.ll` and
`basic-block-sections-labels.ll`)
- Removed `SHT_LLVM_BB_ADDR_MAP_V0` tests. Full deprecation of
`SHT_LLVM_BB_ADDR_MAP_V0` and `SHT_LLVM_BB_ADDR_MAP` version less than 2
will happen in a separate PR in a few months.
This patch adds in support for symbolizing PGO information contained
within the SHT_LLVM_BB_ADDR_MAP section in llvm-objdump. The outputs are
simply the raw values contained within the section.
Previously, some tools such as `clang` or `lld` which require strict
order for certain command-line options, such as `clang -cc1` or `lld
-flavor`, would not longer work on Windows, when these tools were linked
as part of `llvm-driver`. This was caused by `InitLLVM` which was part
of the `*_main()` function of these tools, which in turn calls
`windows::GetCommandLineArguments`. That function completly replaces
argc/argv by new UTF-8 contents, so any ajustements to argc/argv made by
`llvm-driver` prior to calling these tools was reset.
`InitLLVM` is now called by the `llvm-driver`. Any tool that
participates in (or is part of) the `llvm-driver` doesn't call
`InitLLVM` anymore.
This presents misleading and confusing output. If you have a function
defined at the beginning of an XCOFF object file, and you have a
function call to an external function, the function call disassembles as
a branch to the local function. That is,
`void f() { f(); g();}`
disassembles as
>00000000 <.f>:
0: 7c 08 02 a6 mflr 0
4: 94 21 ff c0 stwu 1, -64(1)
8: 90 01 00 48 stw 0, 72(1)
c: 4b ff ff f5 bl 0x0 <.f>
10: 4b ff ff f1 bl 0x0 <.f>
With this PR, the second call will display:
`10: 4b ff ff f1 bl 0x0 <.g> `
Using -r can help, but you still get the confusing output:
>10: 4b ff ff f1 bl 0x0 <.f>
00000010: R_RBR .g