The existing pretty printer generates excessive parentheses for
MCBinaryExpr expressions. This update removes unnecessary parentheses
of MCBinaryExpr with +/- operators and MCUnaryExpr.
Since relocatable expressions only use + and -, this change improves
readability in most cases.
Examples:
- (SymA - SymB) + C now prints as SymA - SymB + C.
This updates the output of -fexperimental-relative-c++-abi-vtables for
AArch64 and x86 to `.long _ZN1B3fooEv@PLT-_ZTV1B-8`
- expr + (MCTargetExpr) now prints as expr + MCTargetExpr, with this
change primarily affecting AMDGPUMCExpr.
From GFX10 onwards it is possible to employ benevolent scheduling of
waves. This patch unconditionally enables, for the `amdhsa` OS, the bit
which controls that capability, as it is beneficial for algorithms that
rely on more complex concurrent coordination and it is generally
performance neutral otherwise.
and fix crash when vd_aux is invalid (#86611).
vd_version, vd_flags, vd_ndx, and vd_cnt in Elf{32,64}_Verdef are
16-bit. Change VerDef to use uint16_t instead.
vda_name specifies a NUL-terminated string. Update getVersionDefinitions
to remove some `.c_str()`.
Pull Request: https://github.com/llvm/llvm-project/pull/128434
The dynamic string table used by the dynamic section is referenced by
the sh_link field of that section, so we should use that directly,
rather than going via the dynamic symbol table.
More info:
https://github.com/llvm/llvm-project/pull/125679#discussion_r1961333454
Signed-off-by: Ruoyu Qiu <cabbaken@outlook.com>
[AMDGPU][NFC] Replace gfx940 and gfx941 with gfx942 in llvm/test
gfx940 and gfx941 are no longer supported. This is one of a series of PRs to remove them from the code base.
This PR uses gfx942 instead of gfx940 and gfx941 in the test RUN-lines (unless there is already a RUN-line for gfx942).
The only notable difference in the test output is that gfx942 does not force the use of sc0 and sc1 on stores while gfx940 and gfx941 do (cf. https://reviews.llvm.org/D149986).
For SWDEV-512631
Adds support to objdump and readobj for reading the `UOP_Epilog` entries
of Windows x64 unwind v2.
`UOP_Epilog` has a weird format:
The first `UOP_Epilog` in the unwind data is the "header":
* The least-significant bit of `OpInfo` is the "At End" flag, which
signifies that there is an epilog at the very end of the associated
function.
* `CodeOffset` is the length each epilog described by the current unwind
information (all epilogs have the same length).
Any subsequent `UOP_Epilog` represents another epilog for the current
function, where `OpInfo` and `CodeOffset` are combined to a 12-bit value
which is the offset of the beginning of the epilog from the end of the
current function. If the offset is 0, then this entry is actually
padding and can be ignored.
This patch introduces a new generic target, `gfx9-4-generic`. Since it doesn’t support FP8 and XF32-related instructions, the patch includes several code reorganizations to accommodate these changes.
Utilize common API in PPCTargetParser
(https://github.com/llvm/llvm-project/pull/97541) to set default CPU
with same interfaces for LLC.
This will update AIX default CPU to pwr7 and LoP powerppc64 default CPU
to ppc64.
WithMarkup objects may nest, resulting in the `)` in `leaq
(%rdx,%rax), %rbx` to be green instead of the default color,
mismatching the color of `(`.
```
% llvm-mc -triple=x86_64 -mdis <<< '0x48 0x8d 0x1c 0x02'
.text
leaq <mem:(<reg:%rdx>,<reg:%rax>)>, <reg:%rbx>
```
To ensure that `(` and `)` get the same color, maintain a color stack
within MCInstPrinter.
Fix#99661
Pull Request: https://github.com/llvm/llvm-project/pull/113834
Swap `!DisassembleZeroes` and `if (DumpARMELFData)` conditions so that
in the false DisassembleZeroes case (default), `...` will be printed for
long consecutive zeroes, even when a data mapping symbol is active.
This is especially useful for certain lld tests that insert a huge
padding within a code section. Without `...` the output will be huge.
Pull Request: https://github.com/llvm/llvm-project/pull/109553
Before llvm20, (void)__sync_fetch_and_add(...) always generates locked
xadd insns. In linux kernel upstream discussion [1], it is found that
for arm64 architecture, the original semantics of
(void)__sync_fetch_and_add(...), i.e., __atomic_fetch_add(...), is
preferred in order for jit to emit proper native barrier insns.
In llvm commits [2] and [3], (void)__sync_fetch_and_add(...) will
generate the following insns:
- for cpu v1/v2: locked xadd insns to keep backward compatibility
- for cpu v3/v4: __atomic_fetch_add() insns
To ensure proper barrier semantics for (void)__sync_fetch_and_add(...),
cpu v3/v4 is recommended.
This patch enables cpu=v3 as the default cpu version. For users wanting
to use cpu v1, -mcpu=v1 needs to be explicitly added to clang/llc
command line.
[1]
https://lore.kernel.org/bpf/ZqqiQQWRnz7H93Hc@google.com/T/#mb68d67bc8f39e35a0c3db52468b9de59b79f021f
[2] https://github.com/llvm/llvm-project/pull/101428
[3] https://github.com/llvm/llvm-project/pull/106494
In a mach_header, the cpusubtype is a 32-bit field, but it's split in 2
subfields:
- the low 24 bits containing the cpu subtype proper, (e.g.,
CPU_SUBTYPE_ARM64E 2)
- the high 8 bits containing a capability field used for additional
feature flags.
Notably, it's only the subtype subfield that participates in fat file
slice discrimination: the caps are ignored.
arm64e uses the caps subfield to encode a ptrauth ABI version:
- 0x80 (CPU_SUBTYPE_PTRAUTH_ABI) denotes a versioned binary
- 0x40 denotes a kernel-ABI binary
- 0x00-0x0F holds the ptrauth ABI version
This teaches the basic obj tools to decode that (or ignore it when
unneeded).
It also teaches the MachO writer to default to emitting versioned
binaries, but with a version of 0 (and without the kernel ABI flag).
Modern arm64e requires versioned binaries: a binary with 0x00 caps in
cpusubtype is now rejected by the linker and everything after. We can
live without the sophistication of specifying the version and kernel ABI
for now.
Co-authored-by: Francis Visoiu Mistrih <francisvm@apple.com>
This feature provided CPM_IOACC_CTL_EL3, a lone system register that has
been carried over since the original ARM64 implementation, where it was
the only processor-specific register in a long list of architectural
sysregs. We don't need it here.
It's been used as a generic processor-specific sysreg in tests, but the
functionality they target is now better covered in other more exhaustive
tests.
The section field has been repurposed for some STAB symbol types, and if
we blindly look it up we'll produce an error and terminate. Logic
already existed
Existing stabs test had a section that was in range. Unfortunately I
don't know of an easy way to produce stabs entries in LLVM (I thought
they died in the 90s until this came up) so I just binary-edited it to
cause a failure on existing llvm-objdump.
llvm-objdump -S issues unnecessary warnings for RISC-V relocatable files
containing .debug_loclists or .debug_rnglists sections with ULEB128
relocations. This occurred because `DWARFObjInMemory` verifies support for all
relocation types, triggering warnings for unsupported ones.
```
% llvm-objdump -S a.o
...
0000000000000000 <foo>:
warning: failed to compute relocation: R_RISCV_SUB_ULEB128, Invalid data was encountered while parsing the file
warning: failed to compute relocation: R_RISCV_SET_ULEB128, Invalid data was encountered while parsing the file
...
```
This change fixes#101544 by declaring support for the two ULEB128
relocation types, silencing the spurious warnings.
---
In DWARF v5 builds, DW_LLE_offset_pair/DW_RLE_offset_pair might be
generated in .debug_loclists/.debug_rnglists with ULEB128 relocations.
They are only read by llvm-dwarfdump to dump section content and verbose
DW_AT_location/DW_AT_ranges output for relocatable files.
The DebugInfoDWARF user (e.g. DWARFDebugRnglists.cpp) calls
`Data.getULEB128` without checking the ULEB128 relocations, as the
unrelocated value holds meaning (refer to the assembler
implementation https://reviews.llvm.org/D157657). This differs from
`.quad .Lfoo`, which requires relocation reading (e.g.
https://reviews.llvm.org/D74404).
Pull Request: https://github.com/llvm/llvm-project/pull/101607
Enable local labels computation for BPF disassembly when
`--symbolize-operands` option is specified.
This relies on `MCInstrAnalysis::evaluateBranch()` method, which is
already defined in `BPFMCInstrAnalysis::evaluateBranch`.
After this change the assembly code below:
if r1 > 42 goto +1
r1 -= 10
...
Would be printed as:
if r1 > 42 goto +1 <L0>
r1 -= 10
<L0>:
...
(when `--symbolize-operands` option is set).
See https://reviews.llvm.org/D84191 for the main part of the
`--symbolize-operands` implementation logic.
Add `createLocalSymbol` to create a local, non-temporary symbol.
Different from `createRenamableSymbol`, the `Used` bit is ignored,
therefore multiple local symbols might share the same name.
Utilizing `createLocalSymbol` in AArch64 allows for efficient mapping
symbol creation with non-unique names, saving .strtab space.
The behavior matches GNU assembler.
Pull Request: https://github.com/llvm/llvm-project/pull/99836
The design of the export trie in macho's is that each node has a
variable length payload. When reading nodes, it should be an error if
reading the uleb128 puts you beyond the stated node size but not when
the stated size goes beyond the known part that was read.
resolves: rdar://130310832
This was primarily authored by Nick Kledzik, I added/cleaned up the test
cases.
Extract the llvm-readelf decoder to `decodeCrel` (#91280) and reuse it
for llvm-objdump.
Because the section representation of LLVMObject (`SectionRef`) is
64-bit, insufficient to hold all decoder states, `section_rel_begin` is
modified to decode CREL eagerly and hold the decoded relocations inside
ELFObjectFile<ELFT>.
The test is adapted from llvm/test/tools/llvm-readobj/ELF/crel.test.
Pull Request: https://github.com/llvm/llvm-project/pull/97382
This test currently has an explicit regex for characters that are
supposedly valid inside a directory name -- however, it does not
actually cover all necessary characters. For example, this test fails if
the path contains a tilde.
Instead, replace this with a wildcard.
Extensions starting with 's' or 'x' should always be followed by an
alphabetical character. I don't know of any crashes from this currently,
but it seemed better to be defensive.
When reading the dynamic string table, llvm-objdump used to crash if the
ELF was malformed, due to an erroneous consumption of error status.
Instead, propogate the error status to the caller, fixing the crash, and
printing a warning.
`macho-relative-method-lists.test` is failing on little endian
platforms, when matching 'name'.
```
CHK32-NEXT: name 0x144 (0x{{[0-9a-f]*}}) instance_method_00
next:10'0 X error: no match found
18: name 0x144 (0x7ac)
```
This seems like the obvious fix.
Co-authored-by: Alex B <alexborcan@meta.com>
After commit 9d5edfde5c3dbc4eb559d316e82e664f291fc2bf the test is failing on the AIX bot. XFAIL for now to unblock the bot and give time to investigate.
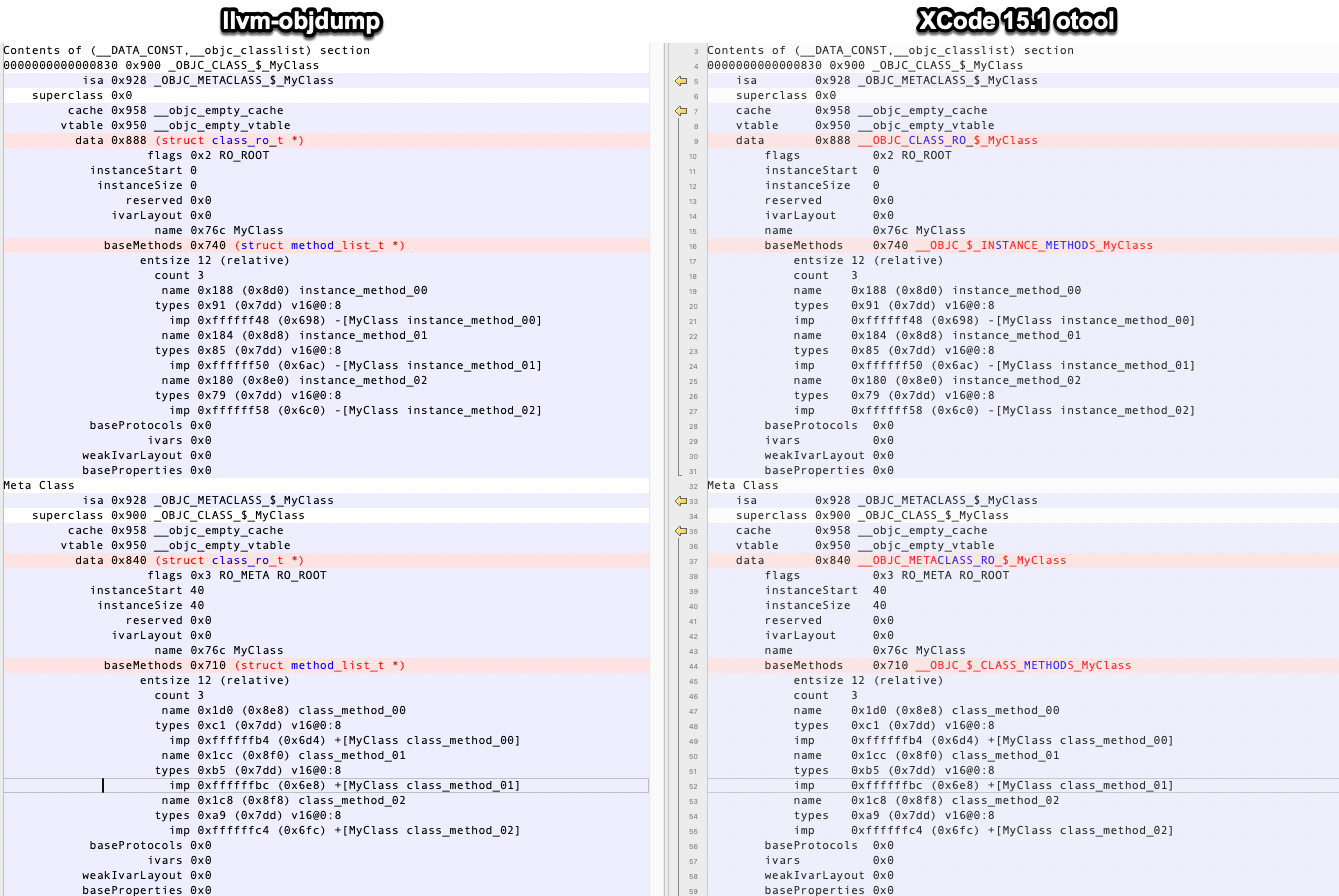
For Mach-O, ld64 supports the -fobjc-relative-method-lists flag which
changes the format in which method lists are generated. The format uses
delta encoding vs the original direct-pointer encoding.
This change adds support to llvm-objdump and llvm-otool for
decoding/dumping of method lists in the delta format. Previously, if a
binary with this information format was passed to the tooling, it would
output invalid information, trying to parse the delta lists as pointer
lists.
After this change, the tooling will output correct information if a
binary in this format is encountered.
The output format is closest feasible match to XCode 15.1's otool
output. Tests are included for both 32bit and 64bit binaries.
The code style was matched as close as possible to existing
implementation of parsing non-delta method lists.
Diff between llvm-objdump and XCode 15.1 otool:

Note: This is a retry of this PR:
https://github.com/llvm/llvm-project/pull/84250
On the original PR, the armv7+armv8 builds were failing due to absolute
offsets being different.
Co-authored-by: Alex B <alexborcan@meta.com>
For Mach-O, ld64 supports the `-fobjc-relative-method-lists` flag which
changes the format in which method lists are generated. The format uses
delta encoding vs the original direct-pointer encoding.
This change adds support to `llvm-objdump` and `llvm-otool` for
decoding/dumping of method lists in the delta format. Previously, if a
binary with this information format was passed to the tooling, it would
output invalid information, trying to parse the delta lists as pointer
lists.
After this change, the tooling will output correct information if a
binary in this format is encountered.
The output format is closest feasible match to XCode 15.1's otool
output. Tests are included for both 32bit and 64bit binaries.
The code style was matched as close as possible to existing
implementation of parsing non-delta method lists.
Diff between llvm-objdump and XCode 15.1 otool:
---------
Co-authored-by: Alex B <alexborcan@meta.com>
Primary change is to add a flag `--pretty-pgo-analysis-map` to
llvm-readobj and llvm-objdump that prints block frequencies and branch
probabilities in the same manner as BFI and BPI respectively. This can
be helpful if you are manually inspecting the outputs from the tools.
In order to print, I moved the `printBlockFreqImpl` function from
Analysis to Support and renamed it to `printRelativeBlockFreq`.