`SmallVector` has a special case to allow vector of char to exceed 4 GB
in
size on 64-bit hosts. Apply this special case only for 8-bit element
types, instead of all element types < 32 bits.
This makes `SmallVector<MCPhysReg>` more compact because `MCPhysReg` is
`uint16_t`.
---------
Co-authored-by: Nikita Popov <github@npopov.com>
LLVM's build system does the right thing but LLVM_SYSTEM_LIBS ends up
containing the shared library. Emit the static library instead when
appropriate.
With LLVM_USE_STATIC_ZSTD, before:
khuey@zhadum:~/dev/llvm-project/build$ ./bin/llvm-config --system-libs
-lrt -ldl -lm -lz -lzstd -lxml2
after:
khuey@zhadum:~/dev/llvm-project/build$ ./bin/llvm-config --system-libs
-lrt -ldl -lm -lz /usr/local/lib/libzstd.a -lxml2
The two variables using ManagedStatic that are exported by this
header are not actually used anywhere -- they are used through
SubCommand::getTopLevel() and SubCommand::getAll() instead.
Drop the extern declarations and the include.
### Context
We have a longstanding performance issue on Windows, where to this day,
the default heap allocator is still lockfull. With the number of cores
increasing, building and using LLVM with the default Windows heap
allocator is sub-optimal. Notably, the ThinLTO link times with LLD are
extremely long, and increase proportionally with the number of cores in
the machine.
In
a6a37a2fcd,
I introduced the ability build LLVM with several popular lock-free
allocators. Downstream users however have to build their own toolchain
with this option, and building an optimal toolchain is a bit tedious and
long. Additionally, LLVM is now integrated into Visual Studio, which
AFAIK re-distributes the vanilla LLVM binaries/installer. The point
being that many users are impacted and might not be aware of this
problem, or are unable to build a more optimal version of the toolchain.
The symptom before this PR is that most of the CPU time goes to the
kernel (darker blue) when linking with ThinLTO:
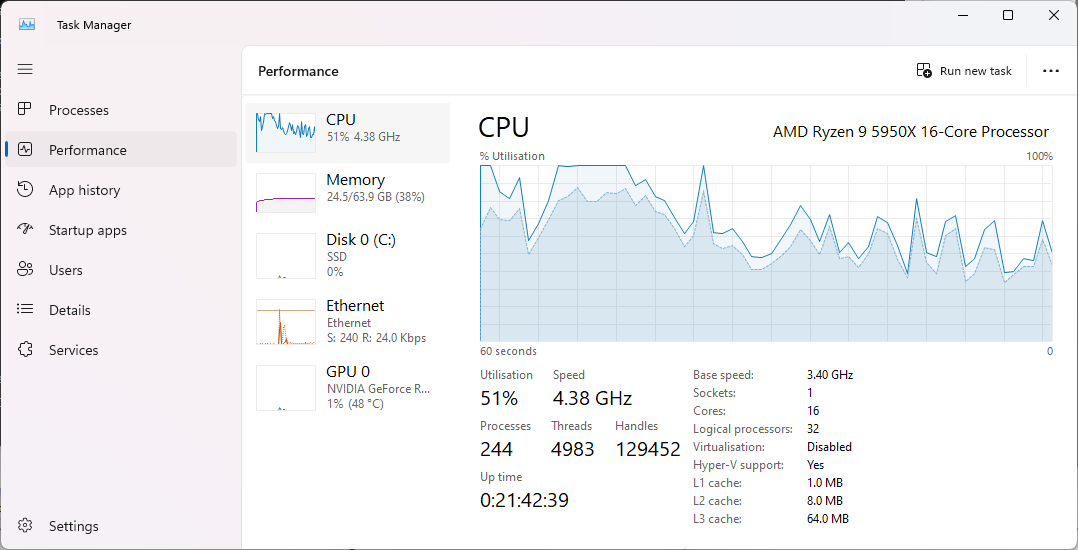
With this PR, most time is spent in user space (light blue):

On higher core count machines, before this PR, the CPU usage becomes
pretty much flat because of contention:
<img width="549" alt="VM_176_windows_heap"
src="https://github.com/llvm/llvm-project/assets/37383324/f27d5800-ee02-496d-a4e7-88177e0727f0">
With this PR, similarily most CPU time is now used:
<img width="549" alt="VM_176_with_rpmalloc"
src="https://github.com/llvm/llvm-project/assets/37383324/7d4785dd-94a7-4f06-9b16-aaa4e2e505c8">
### Changes in this PR
The avenue I've taken here is to vendor/re-licence rpmalloc in-tree, and
use it when building the Windows 64-bit release. Given the permissive
rpmalloc licence, prior discussions with the LLVM foundation and
@lattner suggested this vendoring. Rpmalloc's author (@mjansson) kindly
agreed to ~~donate~~ re-licence the rpmalloc code in LLVM (please do
correct me if I misinterpreted our past communications).
I've chosen rpmalloc because it's small and gives the best value
overall. The source code is only 4 .c files. Rpmalloc is statically
replacing the weak CRT alloc symbols at link time, and has no dynamic
patching like mimalloc. As an alternative, there were several
unsuccessfull attempts made by Russell Gallop to use SCUDO in the past,
please see thread in https://reviews.llvm.org/D86694. If later someone
comes up with a PR of similar performance that uses SCUDO, we could then
delete this vendored rpmalloc folder.
I've added a new cmake flag `LLVM_ENABLE_RPMALLOC` which essentialy sets
`LLVM_INTEGRATED_CRT_ALLOC` to the in-tree rpmalloc source.
### Performance
The most obvious test is profling a ThinLTO linking step with LLD. I've
used a Clang compilation as a testbed, ie.
```
set OPTS=/GS- /D_ITERATOR_DEBUG_LEVEL=0 -Xclang -O3 -fstrict-aliasing -march=native -flto=thin -fwhole-program-vtables -fuse-ld=lld
cmake -G Ninja %ROOT%/llvm -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_ASSERTIONS=TRUE -DLLVM_ENABLE_PROJECTS="clang" -DLLVM_ENABLE_PDB=ON -DLLVM_OPTIMIZED_TABLEGEN=ON -DCMAKE_C_COMPILER=clang-cl.exe -DCMAKE_CXX_COMPILER=clang-cl.exe -DCMAKE_LINKER=lld-link.exe -DLLVM_ENABLE_LLD=ON -DCMAKE_CXX_FLAGS="%OPTS%" -DCMAKE_C_FLAGS="%OPTS%" -DLLVM_ENABLE_LTO=THIN
```
I've profiled the linking step with no LTO cache, with Powershell, such
as:
```
Measure-Command { lld-link /nologo @CMakeFiles\clang.rsp /out:bin\clang.exe /implib:lib\clang.lib /pdb:bin\clang.pdb /version:0.0 /machine:x64 /STACK:10000000 /DEBUG /OPT:REF /OPT:ICF /INCREMENTAL:NO /subsystem:console /MANIFEST:EMBED,ID=1 }`
```
Timings:
| Machine | Allocator | Time to link |
|--------|--------|--------|
| 16c/32t AMD Ryzen 9 5950X | Windows Heap | 10 min 38 sec |
| | **Rpmalloc** | **4 min 11 sec** |
| 32c/64t AMD Ryzen Threadripper PRO 3975WX | Windows Heap | 23 min 29
sec |
| | **Rpmalloc** | **2 min 11 sec** |
| | **Rpmalloc + /threads:64** | **1 min 50 sec** |
| 176 vCPU (2 socket) Intel Xeon Platinium 8481C (fixed clock 2.7 GHz) |
Windows Heap | 43 min 40 sec |
| | **Rpmalloc** | **1 min 45 sec** |
This also improves the overall performance when building with clang-cl.
I've profiled a regular compilation of clang itself, ie:
```
set OPTS=/GS- /D_ITERATOR_DEBUG_LEVEL=0 /arch:AVX -fuse-ld=lld
cmake -G Ninja %ROOT%/llvm -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_ASSERTIONS=TRUE -DLLVM_ENABLE_PROJECTS="clang;lld" -DLLVM_ENABLE_PDB=ON -DLLVM_OPTIMIZED_TABLEGEN=ON -DCMAKE_C_COMPILER=clang-cl.exe -DCMAKE_CXX_COMPILER=clang-cl.exe -DCMAKE_LINKER=lld-link.exe -DLLVM_ENABLE_LLD=ON -DCMAKE_CXX_FLAGS="%OPTS%" -DCMAKE_C_FLAGS="%OPTS%"
```
This saves approx. 30 sec when building on the Threadripper PRO 3975WX:
```
(default Windows Heap)
C:\src\git\llvm-project>hyperfine -r 5 -p "make_llvm.bat stage1_test2" "ninja clang -C stage1_test2"
Benchmark 1: ninja clang -C stage1_test2
Time (mean ± σ): 392.716 s ± 3.830 s [User: 17734.025 s, System: 1078.674 s]
Range (min … max): 390.127 s … 399.449 s 5 runs
(rpmalloc)
C:\src\git\llvm-project>hyperfine -r 5 -p "make_llvm.bat stage1_test2" "ninja clang -C stage1_test2"
Benchmark 1: ninja clang -C stage1_test2
Time (mean ± σ): 360.824 s ± 1.162 s [User: 15148.637 s, System: 905.175 s]
Range (min … max): 359.208 s … 362.288 s 5 runs
```
Add a 128-bit xxhash function, following the existing
`llvm::xxh3_64bits` and `llvm::xxHash` implementations. Previously,
48e93f57f1ee914ca29aa31bf2ccd916565a3610 added support for
`llvm::xxh3_64bits`, which closely follows the upstream implementation
at https://github.com/Cyan4973/xxHash, with simplifications from Devin
Hussey's xxhash-clean.
However, it is desirable to have a larger 128-bit hash key for use cases
such as filesystem checksums where chance of collision needs to be
negligible.
So to that end this also ports over the 128-bit xxh3_128bits as
`llvm::xxh3_128bits`.
Testing:
- Add a test based on xsum_sanity_check.c in upstream xxhash.
This PR depends on https://github.com/llvm/llvm-project/pull/90264
In the current implementation, only leaf children of each internal node
in the suffix tree are included as candidates for outlining. But all
leaf descendants are outlining candidates, which we include in the new
implementation. This is enabled on a flag `outliner-leaf-descendants`
which is default to be true.
The reason for _enabling this on a flag_ is because machine outliner is
not the only pass that uses suffix tree.
The reason for _having this default to be true_ is because including all
leaf descendants show consistent size win.
* For Clang/LLD, it shows around 3% reduction in text segment size when
compared to the baseline `-Oz` linker binary.
* For selected benchmark tests in LLVM test suite
| run (CTMark/) | only leaf children | all leaf descendants | reduction
% |
|------------------|--------------------|----------------------|-------------|
| lencod | 349624 | 348564 | -0.2004% |
| SPASS | 219672 | 218440 | -0.4738% |
| kc | 271956 | 250068 | -0.4506% |
| sqlite3 | 223920 | 222484 | -0.5471% |
| 7zip-benchmark | 405364 | 401244 | -0.3428% |
| bullet | 139820 | 138340 | -0.8315% |
| consumer-typeset | 295684 | 286628 | -1.2295% |
| pairlocalalign | 72236 | 71936 | -0.2164% |
| tramp3d-v4 | 189572 | 183676 | -2.9668% |
This is part of an enhanced version of machine outliner -- see
[RFC](https://discourse.llvm.org/t/rfc-enhanced-machine-outliner-part-1-fulllto-part-2-thinlto-nolto-to-come/78732).
This finally wraps the now-lightly-modified SipHash C reference
implementation, for the main interface we need (16-bit ptrauth
discriminators).
The exact algorithm is the little-endian interpretation of the
non-doubled (i.e. 64-bit) result of applying a SipHash-2-4 using the
constant seed `b5d4c9eb79104a796fec8b1b428781d4` (big-endian), with the
result reduced by modulo to the range of non-zero discriminators (i.e.
`(rawHash % 65535) + 1`).
By "stable" we mean that the result of this hash algorithm will the same
across different compiler versions and target platforms.
The 16-bit hashes are used extensively for the AArch64 ptrauth ABI,
because AArch64 can efficiently load a 16-bit immediate into the high
bits of a register without disturbing the remainder of the value, which
serves as a nice blend operation.
16 bits is also sufficiently compact to not inflate a loader relocation.
We disallow zero to guarantee a different discriminator from the places
in the ABI that use a constant zero.
Co-authored-by: John McCall <rjmccall@apple.com>
Start building it as part of the library, with some minor
tweaks compared to the reference implementation:
- clang-format to match libSupport
- remove tracing support
- add file header
- templatize cROUNDS/dROUNDS, as well as 8B/16B result length
- replace assert with static_assert
- use LLVM_FALLTHROUGH
This also exports interfaces for SipHash-2-4-64/-128, and
tests them using the reference test vectors.
This brings the unmodified SipHash reference implementation:
https://github.com/veorq/SipHash
which has been very graciously licensed under our llvm license
(Apache-2.0 WITH LLVM-exception) by Jean-Philippe Aumasson.
SipHash is a lightweight hash function optimized for speed on short
messages. We use it as part of the AArch64 ptrauth ABI (in arm64e and
ELF PAuth) to generate discriminators based on language identifiers and
mangled names.
This commit brings the unmodified reference implementation and tests
as of f26d35e, specifically siphash.c and vectors.h, as SipHash.cpp and
SipHashTest.cpp.
Next, we will integrate it properly into libSupport, with a wrapping API
suited for the ptrauth use-case.
The previous check was false when compiling with `clang++`, which
prevented `ntdll` from being specified as a link library, causing an
undefined symbol error when trying to resolve `RtlGetLastNtStatus`.
Since we always want to link these libraries on Windows, the check can
be simplified to just `if( WIN32 )`.
There are some places that want to convert an Error to string, but still
retain the original Error object, for example to emit a non-fatal
warning.
This currently isn't possible, because the entire Error infra is
move-based. And what people end up doing in this case is to move the
Error... twice.
This patch introduces a toStringWithoutConsuming() function to
accommodate this use case. This also requires some infrastructure that
allows visiting Errors without consuming them.
Change: remove guards on debug-printing, to allow Release builds without
LLVM_ENABLE_DUMP to pass.
MPInt is an arbitrary-precision integer library that builds on top of
APInt, and has a fast-path when the number fits within 64 bits. It was
originally written for the Presburger library in MLIR, but seems useful
to the LLVM project in general, independently of the Presburger library
or MLIR. Hence, move it into LLVM/ADT under the name DynamicAPInt.
This patch is part of a project to move the Presburger library into
LLVM.
MPInt is an arbitrary-precision integer library that builds on top of
APInt, and has a fast-path when the number fits within 64 bits. It was
originally written for the Presburger library in MLIR, but seems useful
to the LLVM project in general, independently of the Presburger library
or MLIR. Hence, move it into LLVM/ADT under the name DynamicAPInt.
This patch is part of a project to move the Presburger library into
LLVM.
When trying to add a file to clang's VFS via `addFile` and a directory
of the same name already exists, we run into a [out-of-bound
access](145815c180/llvm/lib/Support/Path.cpp (L244)).
The problem is that the file name is [recognised as existing path](
145815c180/llvm/lib/Support/VirtualFileSystem.cpp (L896))
and thus continues to process the next part of the path which doesn't
exist.
This patch adds a check if we have reached the last part of the filename
and return false in that case.
This we reject to add a file if a directory of the same name already
exists.
This is in sync with [this
check](145815c180/llvm/lib/Support/VirtualFileSystem.cpp (L903))
that rejects adding a path if a file of the same name already exists.
If a delete is pending on the file queried for status, a misleading
`permission_denied` error code will be returned (this is the correct
mapping of the error set by GetFileAttributesW). By querying the
underlying NTSTATUS code via ntdll's RtlGetLastNtStatus, this case can
be disambiguated. If this underlying error code indicates a pending
delete, fs::status will return a new `pending_delete` error code to be
handled by callers
Fixes#89137
`std::aligned_storage` is deprecated with C++23, see
[here](https://www.open-std.org/jtc1/sc22/wg21/docs/papers/2021/p1413r3.pdf).
This replaces the usages of `std::aligned_storage` within llvm (only one
in ADT and one in Support) with an aligned `std::byte` array.
I will provide patches for other subcomponents as well.
This reverts commit fe82a3da36196157c0caa1ef2505186782f750d1.
This broke LLDB on MacOS due to a missing symbol during linking.
The fix has been applied in c6c08eee37bada190bd1aa4593c88a5e2c8cdaac.
Original commit message:
The terminfo dependency introduces a significant nonhermeticity into the
build. It doesn't respect `--no-undefined-version` meaning that it's not
a dependency that can be built with Clang 17+. This forces maintainers
of source-based distributions to implement patches or ignore linker
errors.
Remove it to reduce the closure size and improve portability of
LLVM-based tools. Users can still use command line arguments to toggle
color support expliticly.
Fixes#75490Closes#53294#23355
- added unittests for the raw_fd_stream output case.
- the `BitstreamWriter` ctor was confusing, the relationship between the buffer and the file stream wasn't clear and in fact there was a potential bug in `BitcodeWriter` in the mach-o case, because that code assumed in-buffer only serialization. The incremental flushing behavior of flushing at end of block boundaries was an implementation detail that meant serializers not using blocks (for example) would need to know to check the buffer and flush. The bug was latent - in the sense that, today, because the stream being passed was not a `raw_fd_stream`, incremental buffering never kicked in.
The new design moves the responsibility of flushing to the `BitstreamWriter`, and makes it work with any `raw_ostream` (but incrementally flush only in the `raw_fd_stream` case). If the `raw_ostream` is over a buffer - i.e. a `raw_svector_stream` - then it's equivalent to today's buffer case. For all other `raw_ostream` cases, buffering is an implementation detail. In all cases, the buffer is flushed (well, in the buffer case, that's a moot statement).
This simplifies the state and state transitions the user has to track: you have a raw_ostream -> BitstreamWrite in it -> destroy the writer => the bitstream is completely written in your raw_ostream. The "buffer" case and the "raw_fd_stream" case become optimizations rather than imposing state transition concerns to the user.
This is a second attempt to land #84501 which failed on several targets.
This patch adds the HAS_IEE754_FLOAT128 define which makes the check for
typedef'ing float128 more precise by checking whether __uint128_t is
available and checking if the host does not use __ibm128 which is
prevalent on power pc targets and replaces IEEE754 float128s.
Update the folder titles for targets in the monorepository that have not
seen taken care of for some time. These are the folders that targets are
organized in Visual Studio and XCode
(`set_property(TARGET <target> PROPERTY FOLDER "<title>")`)
when using the respective CMake's IDE generator.
* Ensure that every target is in a folder
* Use a folder hierarchy with each LLVM subproject as a top-level folder
* Use consistent folder names between subprojects
* When using target-creating functions from AddLLVM.cmake, automatically
deduce the folder. This reduces the number of
`set_property`/`set_target_property`, but are still necessary when
`add_custom_target`, `add_executable`, `add_library`, etc. are used. A
LLVM_SUBPROJECT_TITLE definition is used for that in each subproject's
root CMakeLists.txt.
The terminfo dependency introduces a significant nonhermeticity into the
build. It doesn't respect `--no-undefined-version` meaning that it's not
a dependency that can be built with Clang 17+. This forces maintainers
of source-based distributions to implement patches or ignore linker
errors.
Remove it to reduce the closure size and improve portability of
LLVM-based tools. Users can still use command line arguments to toggle
color support expliticly.
Fixes#75490Closes#53294#23355
The current API first creates a temporary std::string, then passes it as
a C string, only to then convert it into a std::string for storage, thus
unnecessarily computing the length of the string and copying it.
If `::poll` returns and `FD` equals -1, then `ListeningSocket::shutdown`
has been called. So, regardless of any other information that could be
gleaned from `FDs.revents` or `PollStatus`, it is appropriate to return
`std::errc::operation_canceled`. `ListeningSocket::shutdown` copies
`FD`'s value to `ObservedFD` then sets `FD` to -1 before canceling
`::poll` by calling `::close(ObservedFD)` and writing to the pipe.
This amends dceaa0f4491ebe30c0b0f1bc7fa5ec365b60ced6 because ASAN
caught an issue where the allocation and deallocation were not properly
paired: https://lab.llvm.org/buildbot/#/builders/239/builds/7001
Use malloc and free throughout this file to ensure that all kinds of
memory buffers use the proper pairing.
When allocating a memory buffer, we use a non-throwing new so that we
can explicitly handle memory buffers that are too large to fit into
memory. However, when exceptions are disabled, LLVM installs a custom
new handler
(90109d4448/llvm/lib/Support/InitLLVM.cpp (L61))
that explicitly crashes when we run out of memory
(de14b749fe/llvm/lib/Support/ErrorHandling.cpp (L188))
and that means this particular out-of-memory situation cannot be
gracefully handled.
This was discovered while working on #embed
(https://github.com/llvm/llvm-project/pull/68620) on Windows and
resulted in a crash rather than the preprocessor issuing a diagnostic as
expected.
This patch switches away from the non-throwing new to a call to malloc
(and free), which will return a null pointer without calling a custom
new handler. It is the only instance in Clang or LLVM that I could find
which used a non-throwing new, so I did not think we would need anything
more involved than this change.
Testing this would be highly platform dependent and so it does not come
with test coverage. And because it doesn't change behavior that users
are likely to be able to observe, it does not come with a release note.
I'm planning to remove StringRef::equals in favor of
StringRef::operator==.
- StringRef::operator==/!= outnumber StringRef::equals by a factor of
70 under llvm/ in terms of their usage.
- The elimination of StringRef::equals brings StringRef closer to
std::string_view, which has operator== but not equals.
- S == "foo" is more readable than S.equals("foo"), especially for
!Long.Expression.equals("str") vs Long.Expression != "str".
The sorting code previously asserted if a prefix was multiple letters,
but didn't start with s, x, or z.
Replace the assert with an explicit check and sort the multi-letter
extension after the known multi-letter prefixes.
Use `VFS.equivalent()`, which follows symlinks, to check if two module
cache paths are equivalent. This prevents a PCH error when building from
a different path that is a symlink of the original.
```
error: PCH was compiled with module cache path '/home/foo/blah/ModuleCache/2IBP1TNT8OR8D', but the path is currently '/data/users/foo/blah/ModuleCache/2IBP1TNT8OR8D'
1 error generated.
```
I'm planning to remove StringRef::equals in favor of
StringRef::operator==.
- StringRef::operator== outnumbers StringRef::equals by a factor of 25
under llvm/ in terms of their usage.
- The elimination of StringRef::equals brings StringRef closer to
std::string_view, which has operator== but not equals.
- S == "foo" is more readable than S.equals("foo"), especially for
!Long.Expression.equals("str") vs Long.Expression != "str".