When reading the dynamic string table, llvm-objdump used to crash if the
ELF was malformed, due to an erroneous consumption of error status.
Instead, propogate the error status to the caller, fixing the crash, and
printing a warning.
`macho-relative-method-lists.test` is failing on little endian
platforms, when matching 'name'.
```
CHK32-NEXT: name 0x144 (0x{{[0-9a-f]*}}) instance_method_00
next:10'0 X error: no match found
18: name 0x144 (0x7ac)
```
This seems like the obvious fix.
Co-authored-by: Alex B <alexborcan@meta.com>
After commit 9d5edfde5c3dbc4eb559d316e82e664f291fc2bf the test is failing on the AIX bot. XFAIL for now to unblock the bot and give time to investigate.
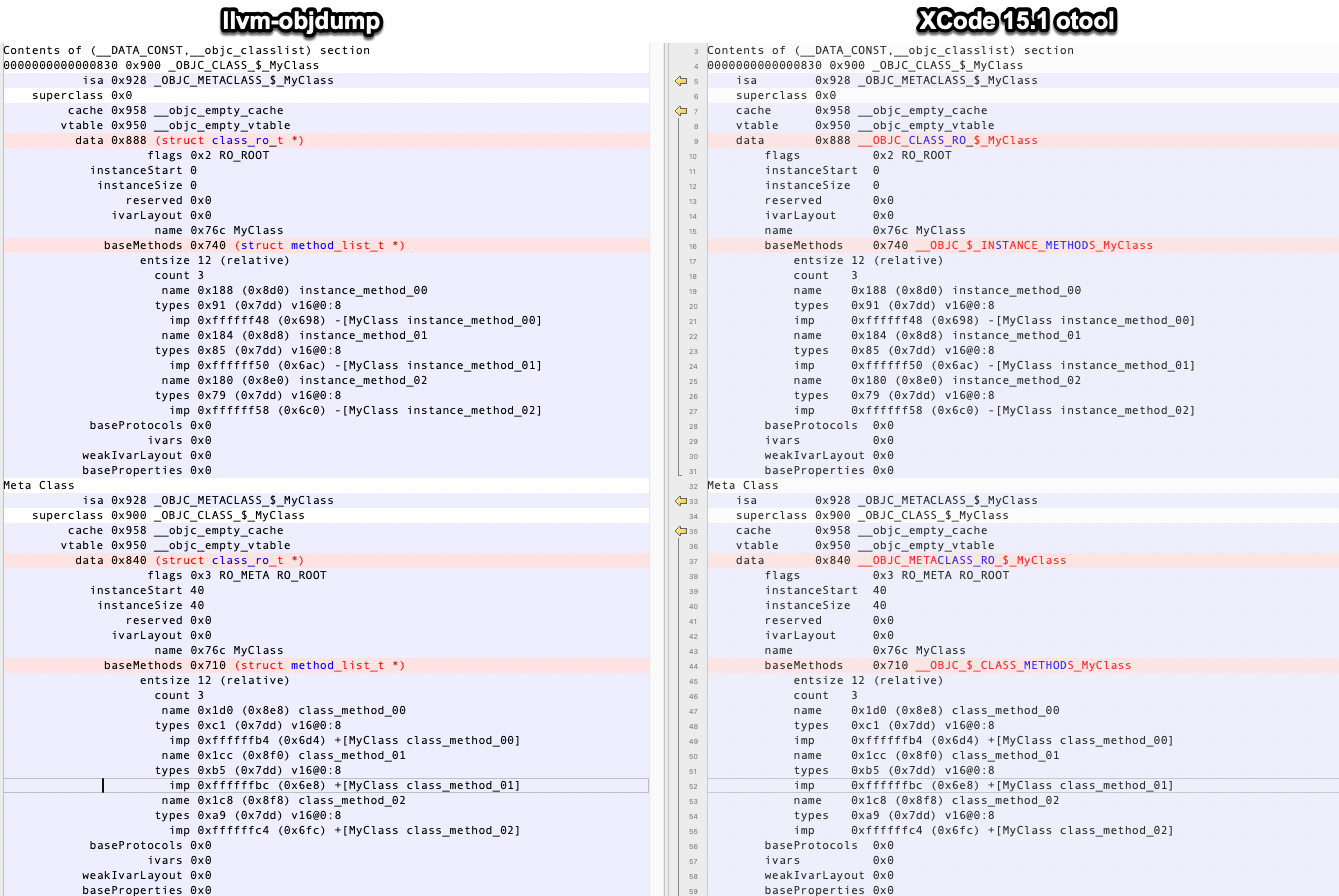
For Mach-O, ld64 supports the -fobjc-relative-method-lists flag which
changes the format in which method lists are generated. The format uses
delta encoding vs the original direct-pointer encoding.
This change adds support to llvm-objdump and llvm-otool for
decoding/dumping of method lists in the delta format. Previously, if a
binary with this information format was passed to the tooling, it would
output invalid information, trying to parse the delta lists as pointer
lists.
After this change, the tooling will output correct information if a
binary in this format is encountered.
The output format is closest feasible match to XCode 15.1's otool
output. Tests are included for both 32bit and 64bit binaries.
The code style was matched as close as possible to existing
implementation of parsing non-delta method lists.
Diff between llvm-objdump and XCode 15.1 otool:

Note: This is a retry of this PR:
https://github.com/llvm/llvm-project/pull/84250
On the original PR, the armv7+armv8 builds were failing due to absolute
offsets being different.
Co-authored-by: Alex B <alexborcan@meta.com>
For Mach-O, ld64 supports the `-fobjc-relative-method-lists` flag which
changes the format in which method lists are generated. The format uses
delta encoding vs the original direct-pointer encoding.
This change adds support to `llvm-objdump` and `llvm-otool` for
decoding/dumping of method lists in the delta format. Previously, if a
binary with this information format was passed to the tooling, it would
output invalid information, trying to parse the delta lists as pointer
lists.
After this change, the tooling will output correct information if a
binary in this format is encountered.
The output format is closest feasible match to XCode 15.1's otool
output. Tests are included for both 32bit and 64bit binaries.
The code style was matched as close as possible to existing
implementation of parsing non-delta method lists.
Diff between llvm-objdump and XCode 15.1 otool:
---------
Co-authored-by: Alex B <alexborcan@meta.com>
Primary change is to add a flag `--pretty-pgo-analysis-map` to
llvm-readobj and llvm-objdump that prints block frequencies and branch
probabilities in the same manner as BFI and BPI respectively. This can
be helpful if you are manually inspecting the outputs from the tools.
In order to print, I moved the `printBlockFreqImpl` function from
Analysis to Support and renamed it to `printRelativeBlockFreq`.
Currently the address reported by binutils for a global is its index;
but its offset (in the file or section) is more useful for binary size
attribution.
This PR treats globals similarly to functions, and tracks their offset
and size. It also centralizes the logic differentiating linked from object
and dylib files (where section addresses are 0).
The dot is too confusing for tools. Output temporaries would have
'10.3-generic' so tools could parse it as an extension, device libs &
the associated clang driver logic are also confused by the dot.
After discussions, we decided it's better to just remove the '.' from
the target name than fix each issue one by one.
These generic targets include multiple GPUs and will, in the future,
provide a way to build once and run on multiple GPU, at the cost of less
optimization opportunities.
Note that this is just doing the compiler side of things, device libs an
runtimes/loader/etc. don't know about these targets yet, so none of them
actually work in practice right now. This is just the initial commit to
make LLVM aware of them.
This contains the documentation changes for both this change and #76954
as well.
nm already prints sizes for data symbols. Do that for function symbols
too, and update objdump to also print size information.
Implements item 3 from https://github.com/llvm/llvm-project/issues/76107
yaml2obj creates invalid object files even when the input was created by
obj2yaml using a valid object file. On the other hand, yaml2obj is used
to intentionally create invalid object files for testing purposes.
This update balances using specified input values when provided and
computing file offsets and sizes if necessary.
Currently symbol info is generated from a linking section or from export
names. This PR generates symbols in a WasmObjectFile from the name
section as well, which allows tools like objdump and nm to show useful
information for more linked binaries. There are some limitations:
most notably that we don't assume any particular ABI, so we don't get
detailed information about data symbols if the segments are merged
(which is the default).
Covers most of the desired functionality from #76107
Wasm has no unified virtual memory space as other object formats and
architectures do, so previously WasmObjectFile reported 0 for all
section addresses, and until 428cf71ff used section offsets for function
symbols. Now we use file offsets for function symbols, and this change
switches section addresses to do the same (in linked files). The main
result of this is that objdump now reports VMAs in section listings, and
also uses file offets rather than section offsets when disassembling
linked binaries (matching the behavior of other disassemblers and stack
traces produced by browwsers). To make this work, this PR also updates
objdump's generation of synthetics fallback symbols to match lib/Object
and also correctly plumbs symbol types for regular and dummy symbols
through to the backend to avoid needing special knowledge of address 0.
This also paves the way for generating symbols from name sections rather
than symbol tables or imports (see #76107) by allowing the
disassembler's synthetic fallback symbols match the name-section
generated symbols (in a followup PR).
C_FILE symbols. To match the behavior of the assembler and the legacy
compiler, this includes using the generic ".file" name for the C_FILE
symbol and generating the actual file name in an auxiliary entry.
Today `-split-machine-functions` and `-fbasic-block-sections={all,list}`
cannot be combined with `-basic-block-sections=labels` (the labels
option will be ignored).
The inconsistency comes from the way basic block address map -- the
underlying mechanism for basic block labels -- encodes basic block
addresses
(https://lists.llvm.org/pipermail/llvm-dev/2020-July/143512.html).
Specifically, basic block offsets are computed relative to the function
begin symbol. This relies on functions being contiguous which is not the
case for MFS and basic block section binaries. This means Propeller
cannot use binary profiles collected from these binaries, which limits
the applicability of Propeller for iterative optimization.
To make the `SHT_LLVM_BB_ADDR_MAP` feature work with basic block section
binaries, we propose modifying the encoding of this section as follows.
First let us review the current encoding which emits the address of each
function and its number of basic blocks, followed by basic block entries
for each basic block.
| | |
|--|--|
| Address of the function | Function Address |
| Number of basic blocks in this function | NumBlocks |
| BB entry 1
| BB entry 2
| ...
| BB entry #NumBlocks
To make this work for basic block sections, we treat each basic block
section similar to a function, except that basic block sections of the
same function must be encapsulated in the same structure so we can map
all of them to their single function.
We modify the encoding to first emit the number of basic block sections
(BB ranges) in the function. Then we emit the address map of each basic
block section section as before: the base address of the section, its
number of blocks, and BB entries for its basic block. The first section
in the BB address map is always the function entry section.
| | |
|--|--|
| Number of sections for this function | NumBBRanges |
| Section 1 begin address | BaseAddress[1] |
| Number of basic blocks in section 1 | NumBlocks[1] |
| BB entries for Section 1
|..................|
| Section #NumBBRanges begin address | BaseAddress[NumBBRanges] |
| Number of basic blocks in section #NumBBRanges |
NumBlocks[NumBBRanges] |
| BB entries for Section #NumBBRanges
The encoding of basic block entries remains as before with the minor
change that each basic block offset is now computed relative to the
begin symbol of its containing BB section.
This patch adds a new boolean codegen option `-basic-block-address-map`.
Correspondingly, the front-end flag `-fbasic-block-address-map` and LLD
flag `--lto-basic-block-address-map` are introduced.
Analogously, we add a new TargetOption field `BBAddrMap`. This means BB
address maps are either generated for all functions in the compiling
unit, or for none (depending on `TargetOptions::BBAddrMap`).
This patch keeps the functionality of the old
`-fbasic-block-sections=labels` option but does not remove it. A
subsequent patch will remove the obsolete option.
We refactor the `BasicBlockSections` pass by separating the BB address
map and BB sections handing to their own functions (named
`handleBBAddrMap` and `handleBBSections`). `handleBBSections` renumbers
basic blocks and places them in their assigned sections.
`handleBBAddrMap` is invoked after `handleBBSections` (if requested) and
only renumbers the blocks.
- New tests added:
- Two tests basic-block-address-map-with-basic-block-sections.ll and
basic-block-address-map-with-mfs.ll to exercise the combination of
`-basic-block-address-map` with `-basic-block-sections=list` and
'-split-machine-functions`.
- A driver sanity test for the `-fbasic-block-address-map` option
(basic-block-address-map.c).
- An LLD test for testing the `--lto-basic-block-address-map` option.
This reuses the LLVM IR from `lld/test/ELF/lto/basic-block-sections.ll`.
- Renamed and modified the two existing codegen tests for basic block
address map (`basic-block-sections-labels-functions-sections.ll` and
`basic-block-sections-labels.ll`)
- Removed `SHT_LLVM_BB_ADDR_MAP_V0` tests. Full deprecation of
`SHT_LLVM_BB_ADDR_MAP_V0` and `SHT_LLVM_BB_ADDR_MAP` version less than 2
will happen in a separate PR in a few months.
This patch adds in support for symbolizing PGO information contained
within the SHT_LLVM_BB_ADDR_MAP section in llvm-objdump. The outputs are
simply the raw values contained within the section.
Similar to 806761a7629df268c8aed49657aeccffa6bca449.
For IR files without a target triple, -mtriple= specifies the full
target triple while -march= merely sets the architecture part of the
default target triple, leaving a target triple which may not make sense,
e.g. amdgpu-apple-darwin.
Therefore, -march= is error-prone and not recommended for tests without
a target triple. The issue has been benign as we recognize
$unknown-apple-darwin as ELF instead of rejecting it outrightly.
This patch changes AMDGPU tests to not rely on the default
OS/environment components. Tests that need fixes are not changed:
```
LLVM :: CodeGen/AMDGPU/fabs.f64.ll
LLVM :: CodeGen/AMDGPU/fabs.ll
LLVM :: CodeGen/AMDGPU/floor.ll
LLVM :: CodeGen/AMDGPU/fneg-fabs.f64.ll
LLVM :: CodeGen/AMDGPU/fneg-fabs.ll
LLVM :: CodeGen/AMDGPU/r600-infinite-loop-bug-while-reorganizing-vector.ll
LLVM :: CodeGen/AMDGPU/schedule-if-2.ll
```
WebAssembly doesn't have a single virtual memory space the way other object
formats or architectures do, so "addresses" mean different things depending
on the context.
Function symbol addresses in object files are offsets from the start of the code
section. This is good for linking and relocation. However when dealing with
linked binaries, offsets from the start of the file/module are more often
used (e.g. for stack traces in browsers), and are more useful for use
cases like binary size attribution. This PR changes Object to use
the file offset instead of the section offset for function symbols, but
only for linked (non-DSO) files.
This is a reland of fc5f51cf with a fix for the MSan failure (it was not caused
by this change, but it was revealed by the new tests).
WebAssembly doesn't have a single virtual memory space the way other
object formats or architectures do, so "addresses" mean different things
depending on the context.
Function symbol addresses in object files are offsets from the start of
the code section. This is good for linking and relocation. However when
dealing with linked binaries, offsets from the start of the file/module
are more often used (e.g. for stack traces in browsers), and are more
useful for use cases like binary size attribution. This PR changes
Object to use the file offset instead of the section offset for function
symbols, but only for linked (non-DSO) files.
This implements item number 4 from #76107
This presents misleading and confusing output. If you have a function
defined at the beginning of an XCOFF object file, and you have a
function call to an external function, the function call disassembles as
a branch to the local function. That is,
`void f() { f(); g();}`
disassembles as
>00000000 <.f>:
0: 7c 08 02 a6 mflr 0
4: 94 21 ff c0 stwu 1, -64(1)
8: 90 01 00 48 stw 0, 72(1)
c: 4b ff ff f5 bl 0x0 <.f>
10: 4b ff ff f1 bl 0x0 <.f>
With this PR, the second call will display:
`10: 4b ff ff f1 bl 0x0 <.g> `
Using -r can help, but you still get the confusing output:
>10: 4b ff ff f1 bl 0x0 <.f>
00000010: R_RBR .g
The current (experimental) spec for WebAssembly shared libraries does
not include a full symbol table like the object format. This change
extracts symbol information from the normal wasm exports.
This is the first step in having the linker report undefined symbols
when linking with shared libraries. The current behaviour is to ignore
all undefined symbols when linking with `-pie` or `-shared`.
See https://github.com/emscripten-core/emscripten/issues/18198
When llvm-objdump switched from cl:: to OptTable
(https://reviews.llvm.org/D100433), we dropped support for LLVM cl::
options. Some LLVM_DEBUG in `llvm/lib/Target/$target/MCDisassembler/`
files might be useful. Add -mllvm to allow dumping the information.
```
# -debug is available in an LLVM_ENABLE_ASSERTIONS=on build
llvm-objdump -d -mllvm -debug a.o > /dev/null
```
Link:
https://discourse.llvm.org/t/how-to-enable-debug-logs-in-llvm-objdump/75758
When a section contains two functions x1 and x2, we incorrectly display
x1's relocations when dumping x2 for `--disassemble-symbols=x2 -r`.
Fix#75539 by ignoring these relocations.
Branch-absolute instructions are currently printed in decimal, and
negative addresses are printed as positive numbers.
With this change, addresses are printed in hex and negative addresses
are converted to an unsigned 32- or 64-bit address.
This patch introduces llvm-objdump tests for new `AARCH64_AUTH_RELR`,
`AARCH64_AUTH_RELRSZ` and `AARCH64_AUTH_RELRENT` dynamic tags.
Depends on https://github.com/llvm/llvm-project/pull/74874
llvm-readobj and llvm-objdump have inconsistent handling of display
lma for sections.
This patch tries to common code up and adapt the same approach for
both tools.
Function evaluateBranch() is used to compute target address for a given
branch instruction and return true on success. But target address of
indirect branch cannot be simply added, so rule it out and just return
false.
This patch also add objdump tests which capture the current state of
support for printing branch targets. Without this patch, the result of
"jirl $zero, $a0, 4" is "jirl $zero, $a0, 4 <foo+0x64>". It is obviously
incorrect, because this instruction represents an indirect branch whose
target address depends on both the register value and the imm. After
this patch, it will be right despite loss of details.
This patch implements `MCInstrAnalysis` state in order to be able
analyze auipc+jalr pairs inside `evaluateBranch`.
This is implemented as follows:
- State: array of currently known GPR values;
- Whenever an auipc is detected in `updateState`, update the state value
of RD with the immediate;
- Whenever a jalr is detected in `evaluateBranch`, check if the state
holds a value for RS1 and use that to compute its target.
Note that this is similar to how binutils implements it and the output
of llvm-objdump should now mostly match the one of GNU objdump.
This patch also updates the relevant llvm-objdump patches and adds a new
one testing the output for interleaved auipc+jalr pairs.
- Be explicit about which program resource register is supported by
which target
- RSRC1
- FP16_OVFL is GFX9+
- WGP_MODE is GFX10+
- MEM_ORDERED is GFX10+
- FWD_PROGRESS is GFX10+
- RSRC3
- INST_PREF_SIZE is GFX11+
- TRAP_ON_START is GFX11+
- TRAP_ON_END is GFX11+
- IMAGE_OP is GFX11+
- Do not emit GFX11+ fields when disassembling GFX10 code objects
- Tighten enforcement of reserved bits in disassembler
---------
Co-authored-by: Konstantin Zhuravlyov <kzhuravl@amd.com>
Extend llvm-objdump to show CO-RE relocations when `-r` option is
passed and object file has .BTF and .BTF.ext sections.
For example, the following C program:
#define __pai __attribute__((preserve_access_index))
struct foo { int i; int j;} __pai;
struct bar { struct foo f[7]; } __pai;
extern void sink(void *);
void root(struct bar *bar) {
sink(&bar[2].f[3].j);
}
Should lead to the following objdump output:
$ clang --target=bpf -O2 -g t.c -c -o - | \
llvm-objdump --no-addresses --no-show-raw-insn -dr -
...
r2 = 0x94
CO-RE <byte_off> [2] struct bar::[2].f[3].j (2:0:3:1)
r1 += r2
call -0x1
R_BPF_64_32 sink
exit
...
More examples could be found in unit tests, see BTFParserTest.cpp.
To achieve this:
- Move CO-RE relocation kinds definitions from BPFCORE.h to BTF.h.
- Extend BTF.h with types derived from BTF::CommonType, e.g.
BTF::IntType and BTF::StrutType, to allow dyn_cast() and access to
type additional data.
- Extend BTFParser to load BTF type and relocation data.
- Modify llvm-objdump.cpp to create instance of BTFParser when
disassembly of object file with BTF sections is processed and `-r`
flag is supplied.
Additional information about CO-RE is available at [1].
[1] https://docs.kernel.org/bpf/llvm_reloc.html
Depends on D149058
Differential Revision: https://reviews.llvm.org/D150079
Add assembler directives for preloading kernel arguments that correspond
to new fields in the kernel descriptor for the length and offset of
arguments that will be placed in SGPRs prior to kernel launch. Alignment
of the arguments in SGPRs is equivalent to the kernarg segment when
accessed via the kernarg_segment_ptr. Kernarg SGPRs are allocated
directly after other user SGPRs.
Reviewed By: arsenm
Differential Revision: https://reviews.llvm.org/D159459
If a virtual register is not assigned preferred physical register, it means some
COPY instructions will be changed to real register move instructions. In this
case we can try to split the virtual register in colder blocks, if success, the
original COPY instructions can be deleted, and the new COPY instructions in
colder blocks will be generated as register move instructions. It results in
fewer dynamic register move instructions executed.
The new test case split-reg-with-hint.ll gives an example, the hot path contains
24 instructions without this patch, now it is only 4 instructions with this
patch.
Differential Revision: https://reviews.llvm.org/D156491