--compress-debug-sections in GNU ld, gas, and LLVM integrated assembler
retain the uncompressed content if the compressed content is larger.
This patch also updates the manpage (-O2 does not enable zlib level 6)
and fixes a crash of --compress-sections when the uncompressed section
is empty.
When enabled, input sections that would otherwise overflow a memory
region are instead spilled to the next matching output section.
This feature parallels the one in GNU LD, but there are some differences
from its documented behavior:
- /DISCARD/ only matches previously-unmatched sections (i.e., the flag
does not affect it).
- If a section fails to fit at any of its matches, the link fails
instead of discarding the section.
- The flag --enable-non-contiguous-regions-warnings is not implemented,
as it exists to warn about such occurrences.
The implementation places stubs at possible spill locations, and
replaces them with the original input section when effecting spills.
Spilling decisions occur after address assignment. Sections are spilled
in reverse order of assignment, with each spill naively decreasing the
size of the affected memory regions. This continues until the memory
regions are brought back under size. Spilling anything causes another
pass of address assignment, and this continues to fixed point.
Spilling after rather than during assignment allows the algorithm to
consider the size effects of unspillable input sections that appear
later in the assignment. Otherwise, such sections (e.g. thunks) may
force an overflow, even if spilling something earlier could have avoided
it.
A few notable feature interactions occur:
- Stubs affect alignment, ONLY_IF_RO, etc, broadly as if a copy of the
input section were actually placed there.
- SHF_MERGE synthetic sections use the spill list of their first
contained input section (the one that gives the section its name).
- ICF occurs oblivious to spill sections; spill lists for merged-away
sections become inert and are removed after assignment.
- SHF_LINK_ORDER and .ARM.exidx are ordered according to the final
section ordering, after all spilling has completed.
- INSERT BEFORE/AFTER and OVERWRITE_SECTIONS are explicitly disallowed.
When enabled, input sections that would otherwise overflow a memory
region are instead spilled to the next matching output section.
This feature parallels the one in GNU LD, but there are some differences
from its documented behavior:
- /DISCARD/ only matches previously-unmatched sections (i.e., the flag
does not affect it).
- If a section fails to fit at any of its matches, the link fails
instead of discarding the section.
- The flag --enable-non-contiguous-regions-warnings is not implemented,
as it exists to warn about such occurrences.
The implementation places stubs at possible spill locations, and
replaces them with the original input section when effecting spills.
Spilling decisions occur after address assignment. Sections are spilled
in reverse order of assignment, with each spill naively decreasing the
size of the affected memory regions. This continues until the memory
regions are brought back under size. Spilling anything causes another
pass of address assignment, and this continues to fixed point.
Spilling after rather than during assignment allows the algorithm to
consider the size effects of unspillable input sections that appear
later in the assignment. Otherwise, such sections (e.g. thunks) may
force an overflow, even if spilling something earlier could have avoided
it.
A few notable feature interactions occur:
- Stubs affect alignment, ONLY_IF_RO, etc, broadly as if a copy of the
input section were actually placed there.
- SHF_MERGE synthetic sections use the spill list of their first
contained input section (the one that gives the section its name).
- ICF occurs oblivious to spill sections; spill lists for merged-away
sections become inert and are removed after assignment.
- SHF_LINK_ORDER and .ARM.exidx are ordered according to the final
section ordering, after all spilling has completed.
- INSERT BEFORE/AFTER and OVERWRITE_SECTIONS are explicitly disallowed.
zstd excels at scaling from low-ratio-very-fast to
high-ratio-pretty-slow. Some users prioritize speed and prefer disk read
speed, while others focus on achieving the highest compression ratio
possible, similar to traditional high-ratio codecs like LZMA.
Add an optional `level` to `--compress-sections` (#84855) to cater to
these diverse needs. While we initially aimed for a one-size-fits-all
approach, this no longer seems to work.
(https://richg42.blogspot.com/2015/11/the-lossless-decompression-pareto.html)
When --compress-debug-sections is used together, make
--compress-sections take precedence since --compress-sections is usually
more specific.
Remove the level distinction between -O/-O1 and -O2 for
--compress-debug-sections=zlib for a more consistent user experience.
Pull Request: https://github.com/llvm/llvm-project/pull/90567
GNU ld added --default-script (alias: -dT) in 2007. The option specifies
a default script that is processed if --script/-T is not specified. -dT
can be used to override GNU ld's internal linker script, but only when
the application does not specify -T.
In addition, dynamorio's CMakeLists.txt may use -dT.
The implementation is simple and the feature can be useful to dabble
with different section layouts.
Pull Request: https://github.com/llvm/llvm-project/pull/89327
`clang -g -gpubnames` (with optional -gsplit-dwarf) creates the
`.debug_names` section ("per-CU" index). By default lld concatenates
input `.debug_names` sections into an output `.debug_names` section.
LLDB can consume the concatenated section but the lookup performance is
not good.
This patch adds --debug-names to create a per-module index by combining
the per-CU indexes into a single index that covers the entire load
module. The produced `.debug_names` is a replacement for `.gdb_index`.
Type units (-fdebug-types-section) are not handled yet.
Co-authored-by: Fangrui Song <i@maskray.me>
---------
Co-authored-by: Fangrui Song <i@maskray.me>
Unknown section sections may require special linking rules, and
rejecting such sections for older linkers may be desired. For example,
if we introduce a new section type to replace a control structure (e.g.
relocations), it would be nice for older linkers to reject the new
section type. GNU ld allows certain unknown section types:
* [SHT_LOUSER,SHT_HIUSER] and non-SHF_ALLOC
* [SHT_LOOS,SHT_HIOS] and non-SHF_OS_NONCONFORMING
but reports errors and stops linking for others (unless
--no-warn-mismatch is specified). Port its behavior. For convenience, we
additionally allow all [SHT_LOPROC,SHT_HIPROC] types so that we don't
have to hard code all known types for each processor.
Close https://github.com/llvm/llvm-project/issues/84812
--compress-sections <section-glib>=[none|zlib|zstd] is similar to
--compress-debug-sections but applies to broader sections without the
SHF_ALLOC flag. lld will report an error if a SHF_ALLOC section is
matched. An interesting use case is to compress `.strtab`/`.symtab`,
which consume a significant portion of the file size (15.1% for a
release build of Clang).
An older revision is available at https://reviews.llvm.org/D154641 .
This patch focuses on non-allocated sections for safety. Moving
`maybeCompress` as D154641 does not handle STT_SECTION symbols for
`-r --compress-debug-sections=zlib` (see `relocatable-section-symbol.s`
from #66804).
Since different output sections may use different compression
algorithms, we need CompressedData::type to generalize
config->compressDebugSections.
GNU ld feature request: https://sourceware.org/bugzilla/show_bug.cgi?id=27452
Link: https://discourse.llvm.org/t/rfc-compress-arbitrary-sections-with-ld-lld-compress-sections/71674
Pull Request: https://github.com/llvm/llvm-project/pull/84855
We recently added `--initial-heap` - an option that allows one to up the
initial memory size without the burden of having to know exactly how
much is needed.
However, in the process of implementing support for this in Emscripten
(https://github.com/emscripten-core/emscripten/pull/21071), we have
realized that `--initial-heap` cannot support the use-case of
non-growable memories by itself, since with it we don't know what to set
`--max-memory` to.
We have thus agreed to move the above work forward by introducing
another option to the linker (see
https://github.com/emscripten-core/emscripten/pull/21071#discussion_r1491755616),
one that would allow users to explicitly specify they want a
non-growable memory.
This change does this by introducing `--no-growable-memory`: an option
that is mutally exclusive with `--max-memory` (for simplicity - we can
also decide that it should override or be overridable by `--max-memory`.
In Emscripten a similar mix of options results in `--no-growable-memory`
taking precedence). The option specifies that the maximum memory size
should be set to the initial memory size, effectively disallowing memory
growth.
Closes#81932.
https://reviews.llvm.org/D150510 places .lrodata before .rodata to
minimize the number of permission transitions in the memory image.
However, this layout is less ideal for -fno-pic code (which is still
important).
Small code model -fno-pic code has R_X86_64_32S relocations with a range
of `[0,2**31)` (if we ignore the negative area). Placing `.lrodata`
earlier exerts relocation pressure on such code. Non-x86 64-bit
architectures generally have a similar `[0,2**31)` limitation if they
don't use PC-relative relocations.
If we place .lrodata later, we will need one extra PT_LOAD. Two layouts
are appealing:
* .bss/.lbss/.lrodata/.ldata (GNU ld)
* .bss/.ldata/.lbss/.lrodata
The GNU ld layout has the nice property that there is only one BSS
(except .tbss/.relro_padding). Add -z lrodata-after-bss to support
this layout.
Since a read-only PT_LOAD segment (for large data sections) may appear
after RW PT_LOAD segments. The placement of `_etext` has to be adjusted.
Pull Request: https://github.com/llvm/llvm-project/pull/81224
The ELF linker transitioned away from archive indexes in
https://reviews.llvm.org/D117284.
This paves the way for supporting `--start-lib`/`--end-lib` (See #77960)
The ELF linker unified library handling with `--start-lib`/`--end-lib` and removed
the ArchiveFile class in https://reviews.llvm.org/D119074.
It is beneficial to preallocate a certain number of pages in the linear
memory (i. e. use the "minimum" field of WASM memories) so that fewer
"memory.grow"s are needed at startup.
So far, the way to do that has been to pass the "--initial-memory"
option to the linker. It works, but has the very significant downside of
requiring the user to know the size of static data beforehand, as it
must not exceed the number of bytes passed-in as "--initial-memory".
The new "--initial-heap" option avoids this downside by simply appending
the specified number of pages to static data (and stack), regardless of
how large they already are.
Ref: https://github.com/emscripten-core/emscripten/issues/20888.
After #71433, lld-link is able to always generate build id even when PDB
is not generated.
This adds the `__buildid` symbol to points to the start of 16 bytes guid
(which is after `RSDS`) and allows profile runtime to access it and dump
it to raw profile.
Edited lld/ELF/Options.td to cdsort as well
CDSort function reordering outperforms the existing default heuristic (
hfsort/C^3) in terms of the performance of generated binaries while
being (almost) as fast. Thus, the suggestion is to change the default.
The speedup is up to 1.5% perf for large front-end binaries, and can be
moderate/neutral for "small" benchmarks.
High-level **perf impact** on two selected binaries:
clang-10 binary (built with LTO+AutoFDO/CSSPGO): wins on top of C^3 in
[0.3%..0.8%]
rocksDB-8 binary (built with LTO+CSSPGO): wins on top of C^3 in
[0.8%..1.5%]
More detailed measurements on the clang binary is at
[here](https://reviews.llvm.org/D152834#4445042)
For an output section with no input section, GNU ld eliminates the
output section when there are only symbol assignments (e.g.
`.foo : { symbol = 42; }`) but not for `.foo : { . += 42; }`
(`SHF_ALLOC|SHF_WRITE`).
We choose to retain such an output section with a symbol assignment
(unless unreferenced `PROVIDE`). We copy the previous section flag (see
https://reviews.llvm.org/D37736) to hopefully make the current PT_LOAD
segment extend to the current output section:
* decrease the number of PT_LOAD segments
* If a new PT_LOAD segment is introduced without a page-size
alignment as a separator, there may be a run-time crash.
However, this `flags` copying behavior is not suitable for
`.foo : { . += 42; }` when `flags` contains `SHF_EXECINSTR`. The
executable bit is surprising
(https://discourse.llvm.org/t/lld-output-section-flag-assignment-behavior/74359).
I think we should drop SHF_EXECINSTR when copying `flags`. The risk is a
code section followed by `.foo : { symbol = 42; }` will be broken, which
I believe is unrelated as such uses are almost always related to data
sections.
For data-command-only output sections (e.g. `.foo : { QUAD(42) }`), we
keep allowing copyable SHF_WRITE.
Some tests are updated to drop the SHF_EXECINSTR flag. GNU ld doesn't
set SHF_EXECINSTR as well, though it sets SHF_WRITE for some tests while
we don't.
CDSort function reordering outperforms the existing default heuristic (
hfsort/C^3) in terms of the performance of generated binaries while
being (almost) as fast. Thus, the suggestion is to change the default.
The speedup is up to 1.5% perf for large front-end binaries, and can be
moderate/neutral for "small" benchmarks.
High-level **perf impact** on two selected binaries:
clang-10 binary (built with LTO+AutoFDO/CSSPGO): wins on top of C^3 in
[0.3%..0.8%]
rocksDB-8 binary (built with LTO+CSSPGO): wins on top of C^3 in
[0.8%..1.5%]
More detailed measurements on the clang binary is at
[here](https://reviews.llvm.org/D152834#4445042)
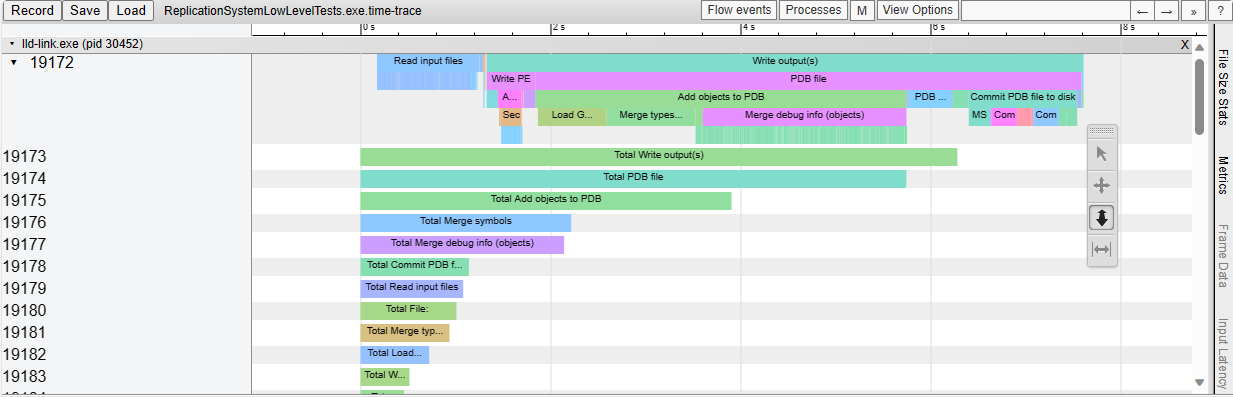
This adds support for generating Chrome-tracing .json profile traces in
the LLD COFF driver.
Also add the necessary time scopes, so that the profile trace shows in
great detail which tasks are executed.
As an example, this is what we see when linking a Unreal Engine
executable:
We are brining a new algorithm for function layout (reordering) based on the
call graph (extracted from a profile data). The algorithm is an improvement of
top of a known heuristic, C^3. It tries to co-locate hot and frequently executed
together functions in the resulting ordering. Unlike C^3, it explores a larger
search space and have an objective closely tied to the performance of
instruction and i-TLB caches. Hence, the name CDS = Cache-Directed Sort.
The algorithm can be used at the linking or post-linking (e.g., BOLT) stage.
Refer to https://reviews.llvm.org/D152834 for the actual implementation of the
reordering algorithm.
This diff adds a linker option to replace the existing C^3 heuristic with CDS.
The new behavior can be turned on by passing "--use-cache-directed-sort".
(the plan is to make it default in a next diff)
**Perf-impact**
clang-10 binary (built with LTO+AutoFDO/CSSPGO): wins on top of C^3 in [0.3%..0.8%]
rocksDB-8 binary (built with LTO+CSSPGO): wins on top of C^3 in [0.8%..1.5%]
Note that function layout affects the perf the most on older machines (with
smaller instruction/iTLB caches) and when huge pages are not enabled. The impact
on newer processors with huge pages enabled is likely neutral/minor.
Reviewed By: MaskRay
Differential Revision: https://reviews.llvm.org/D152840
Change the FF form --call-graph-profile-sort to --call-graph-profile-sort={none,hfsort}.
This will be extended to support llvm/lib/Transforms/Utils/CodeLayout.cpp.
--call-graph-profile-sort is not used in the wild but
--no-call-graph-profile-sort is (Chromium). Make --no-call-graph-profile-sort an
alias for --call-graph-profile-sort=none.
Reviewed By: rahmanl
Differential Revision: https://reviews.llvm.org/D159544
Close#57618: currently we align the end of PT_GNU_RELRO to a
common-page-size
boundary, but do not align the end of the associated PT_LOAD. This is
benign
when runtime_page_size >= common-page-size.
However, when runtime_page_size < common-page-size, it is possible that
`alignUp(end(PT_LOAD), page_size) < alignDown(end(PT_GNU_RELRO),
page_size)`.
In this case, rtld's mprotect call for PT_GNU_RELRO will apply to
unmapped
regions and lead to an error, e.g.
```
error while loading shared libraries: cannot apply additional memory protection after relocation: Cannot allocate memory
```
To fix the issue, add a padding section .relro_padding like mold, which
is contained in the PT_GNU_RELRO segment and the associated PT_LOAD
segment. The section also prevents strip from corrupting PT_LOAD program
headers.
.relro_padding has the largest `sortRank` among RELRO sections.
Therefore, it is naturally placed at the end of `PT_GNU_RELRO` segment
in the absence of `PHDRS`/`SECTIONS` commands.
In the presence of `SECTIONS` commands, we place .relro_padding
immediately before a symbol assignment using DATA_SEGMENT_RELRO_END (see
also https://reviews.llvm.org/D124656), if present.
DATA_SEGMENT_RELRO_END is changed to align to max-page-size instead of
common-page-size.
Some edge cases worth mentioning:
* ppc64-toc-addis-nop.s: when PHDRS is present, do not append
.relro_padding
* avoid-empty-program-headers.s: when the only RELRO section is .tbss,
it is not part of PT_LOAD segment, therefore we do not append
.relro_padding.
---
Close#65002: GNU ld from 2.39 onwards aligns the end of PT_GNU_RELRO to
a
max-page-size boundary (https://sourceware.org/PR28824) so that the last
page is
protected even if runtime_page_size > common-page-size.
In my opinion, losing protection for the last page when the runtime page
size is
larger than common-page-size is not really an issue. Double mapping a
page of up
to max-common-page for the protection could cause undesired VM waste.
Internally
we had users complaining about 2MiB max-page-size applying to shared
objects.
Therefore, the end of .relro_padding is padded to a common-page-size
boundary. Users who are really anxious can set common-page-size to match
their runtime page size.
---
17 tests need updating as there are lots of change detectors.
This adds a new -Bsymbolic option that directly binds all non-weak
symbols. There's a couple of reasons motivating this:
* The new flag will match the default behavior on Mach-O, so you can get
consistent behavior across platforms.
* We have use cases for which making weak data preemptible is useful,
but we don't want to pessimize access to non-weak data. (For a large
internal app, we measured 2000+ data symbols whose accesses would be
unnecessarily pessimized by `-Bsymbolic-functions`.)
Reviewed By: MaskRay
Differential Revision: https://reviews.llvm.org/D158322
This patch adds support to lld for --fat-lto-objects. We add a new
--fat-lto-objects option to LLD, and slightly change how it chooses input
files in the driver when the option is set.
Fat LTO objects contain both LTO compatible IR, as well as generated object
code. This allows users to defer the choice of whether to use LTO or not to
link-time. This is a feature available in GCC for some time, and makes the
existing -ffat-lto-objects option functional in the same way as GCC's.
If the --fat-lto-objects option is passed to LLD and the input files are fat
object files, then the linker will chose the LTO compatible bitcode sections
embedded within the fat object and link them together using LTO. Otherwise,
standard object file linking is done using the assembly section in the object
files.
The previous version of this patch had a missing `REQUIRES: x86` line in
`fatlto.invalid.s`. Additionally, it was reported that this patch caused
a test failure in `export-dynamic-symbols.s`, however,
29112a994694baee070a2021e00f772f1913d214 disabled the
`export-dynamic-symbols.s` test on Windows due to a quotation difference
between platforms, unrelated to this patch.
Original RFC: https://discourse.llvm.org/t/rfc-ffat-lto-objects-support/63977
Reviewed By: MaskRay
Differential Revision: https://reviews.llvm.org/D146778
This adds support for the LoongArch ELF psABI v2.00 [1] relocation
model to LLD. The deprecated stack-machine-based psABI v1 relocs are not
supported.
The code is tested by successfully bootstrapping a Gentoo/LoongArch
stage3, complete with common GNU userland tools and both the LLVM and
GNU toolchains (GNU toolchain is present only for building glibc,
LLVM+Clang+LLD are used for the rest). Large programs like QEMU are
tested to work as well.
[1]: https://loongson.github.io/LoongArch-Documentation/LoongArch-ELF-ABI-EN.html
Reviewed By: MaskRay, SixWeining
Differential Revision: https://reviews.llvm.org/D138135
This reverts commit c9953d9891a6067549a78e7d07ca8eb6a7596792 and a
forward fix in 3a45b843dec1bca195884aa1c5bc56bd0e6755b4.
D14677 causes some failure on windows bots that the forward fix did not
address. Thus I'm reverting until the underlying cause can me triaged.
This patch adds support to lld for --fat-lto-objects. We add a new
--fat-lto-objects flag to LLD, and slightly change how it chooses input
files in the driver when the flag is set.
Fat LTO objects contain both LTO compatible IR, as well as generated object
code. This allows users to defer the choice of whether to use LTO or not to
link-time. This is a feature available in GCC for some time, and makes the
existing -ffat-lto-objects flag functional in the same way as GCC's.
If the --fat-lto-objects option is passed to LLD and the input files are fat
object files, then the linker will chose the LTO compatible bitcode sections
embedded within the fat object and link them together using LTO. Otherwise,
standard object file linking is done using the assembly section in the object
files.
Original RFC: https://discourse.llvm.org/t/rfc-ffat-lto-objects-support/63977
Depends on D146777
Reviewed By: MaskRay
Differential Revision: https://reviews.llvm.org/D146778
We want lld-link to automatically find compiler-rt's and
libc++ when it's in the same directory as the rest of the
toolchain. This is because on Windows linking isn't done
via the clang driver - but instead invoked directly.
This prepends: <llvm>/lib <llvm>/lib/clang/XX/lib and
<llvm>/lib/clang/XX/lib/windows automatically to the library
search paths.
Related to #63827
Differential Revision: https://reviews.llvm.org/D151188
This patch is spun out of https://reviews.llvm.org/D151188
and makes it possible for lld-link to find libraries with
relative paths. This will be used later to implement the
changes to autolinking runtimes explained in #63827
Differential Revision: https://reviews.llvm.org/D155268
Arm has BE8 big endian configuration called a byte-invariant(every byte has the same address on little and big-endian systems).
When in BE8 mode:
1. Instructions are big-endian in relocatable objects but
little-endian in executables and shared objects.
2. Data is big-endian.
3. The data encoding of the ELF file is ELFDATA2MSB.
To support BE8 without an ABI break for relocatable objects,the linker takes on the responsibility of changing the endianness of instructions. At a high level the only difference between BE32 and BE8 in the linker is that for BE8:
1. The linker sets the flag EF_ARM_BE8 in the ELF header.
2. The linker endian reverses the instructions, but not data.
This patch adds BE8 big endian support for Arm. To endian reverse the instructions we'll need access to the mapping symbols. Code sections can contain a mix of Arm, Thumb and literal data. We need to endian reverse Arm instructions as words, Thumb instructions
as half-words and ignore literal data.The only way to find these transitions precisely is by using mapping symbols. The instruction reversal will need to take place after relocation. For Arm BE8 code sections (Section has SHF_EXECINSTR flag ) we inserted a step after relocation to endian reverse the instructions. The implementation strategy i have used here is to write all sections BE32 including SyntheticSections then endian reverse all code in InputSections via mapping symbols.
Reviewed By: peter.smith
Differential Revision: https://reviews.llvm.org/D150870
This reverts commit aa495214b39d475bab24b468de7a7c676ce9e366.
As discussed in https://github.com/llvm/llvm-project/issues/53475 this patch
allows for using LLD-as-a-lib. It also lets clients link only the drivers that
they want (see unit tests).
This also adds the unit test infra as in the other LLVM projects. Among the
test coverage, I've added the original issue from @krzysz00, see:
https://github.com/ROCmSoftwarePlatform/D108850-lld-bug-reproduction
Important note: this doesn't allow (yet) linking in parallel. This will come a
bit later hopefully, in subsequent patches, for COFF at least.
Differential revision: https://reviews.llvm.org/D119049
This is an ongoing series of commits that are reformatting our
Python code. This catches the last of the python files to
reformat. Since they where so few I bunched them together.
Reformatting is done with `black`.
If you end up having problems merging this commit because you
have made changes to a python file, the best way to handle that
is to run git checkout --ours <yourfile> and then reformat it
with black.
If you run into any problems, post to discourse about it and
we will try to help.
RFC Thread below:
https://discourse.llvm.org/t/rfc-document-and-standardize-python-code-style
Reviewed By: jhenderson, #libc, Mordante, sivachandra
Differential Revision: https://reviews.llvm.org/D150784
--remap-inputs-file= can be specified multiple times, each naming a
remap file that contains `from-glob=to-file` lines or `#`-led comments.
('=' is used a separator a la -fdebug-prefix-map=)
--remap-inputs-file= can be used to:
* replace an input file. E.g. `"*/libz.so=exp/libz.so"` can replace a resolved
`-lz` without updating the input file list or (if used) a response file.
When debugging an application where a bug is isolated to one single
input file, this option gives a convenient way to test fixes.
* remove an input file with `/dev/null` (changed to `NUL` on Windows), e.g.
`"a.o=/dev/null"`. A build system may add unneeded dependencies.
This option gives a convenient way to test the result removing some inputs.
`--remap-inputs=a.o=aa.o` can be specified to provide one pattern without using
an extra file.
(bash/zsh process substitution is handy for specifying a pattern without using
a remap file, e.g. `--remap-inputs-file=<(printf 'a.o=aa.o')`, but it may be
unavailable in some systems. An extra file can be inconvenient for a build
system.)
Exact patterns are tested before wildcard patterns. In case of a tie, the first
patterns wins. This is an implementation detail that users should not rely on.
Co-authored-by: Marco Elver <elver@google.com>
Link: https://discourse.llvm.org/t/rfc-support-exclude-inputs/70070
Reviewed By: melver, peter.smith
Differential Revision: https://reviews.llvm.org/D148859
Embedded systems that do not use an ELF loader locate the
.ARM.exidx exception table via linker defined __exidx_start and
__exidx_end rather than use the PT_ARM_EXIDX program header. This
means that some linker scripts such as the picolibc C library's
linker script, do not have the .ARM.exidx sections at offset 0 in
the OutputSection. For example:
.except_unordered : {
. = ALIGN(8);
PROVIDE(__exidx_start = .);
*(.ARM.exidx*)
PROVIDE(__exidx_end = .);
} >flash AT>flash :text
This is within the specification of Arm exception tables, and is
handled correctly by ld.bfd.
This patch has 2 parts. The first updates the writing of the data
of the .ARM.exidx SyntheticSection to account for a non-zero
OutputSection offset. The second part makes the PT_ARM_EXIDX program
header generation a special case so that it covers only the
SyntheticSection and not the parent OutputSection. While not strictly
necessary for programs locating the exception tables via the symbols
it may cause ELF utilities that locate the exception tables via
the PT_ARM_EXIDX program header to fail. This does not seem to be the
case for GNU and LLVM readelf which seems to look for the
SHT_ARM_EXIDX section.
Differential Revision: https://reviews.llvm.org/D148033
This implements support for relaxing these relocations to use the GP
register to compute addresses of globals in the .sdata and .sbss
sections.
This feature is off by default and must be enabled by passing
--relax-gp to the linker.
The GP register might not always be the "global pointer". It can
be used for other purposes. See discussion here
https://github.com/riscv-non-isa/riscv-elf-psabi-doc/pull/371
Reviewed By: MaskRay
Differential Revision: https://reviews.llvm.org/D143673