mirror of
https://github.com/llvm/llvm-project.git
synced 2025-04-27 17:06:05 +00:00
### Context
We have a longstanding performance issue on Windows, where to this day,
the default heap allocator is still lockfull. With the number of cores
increasing, building and using LLVM with the default Windows heap
allocator is sub-optimal. Notably, the ThinLTO link times with LLD are
extremely long, and increase proportionally with the number of cores in
the machine.
In
a6a37a2fcd,
I introduced the ability build LLVM with several popular lock-free
allocators. Downstream users however have to build their own toolchain
with this option, and building an optimal toolchain is a bit tedious and
long. Additionally, LLVM is now integrated into Visual Studio, which
AFAIK re-distributes the vanilla LLVM binaries/installer. The point
being that many users are impacted and might not be aware of this
problem, or are unable to build a more optimal version of the toolchain.
The symptom before this PR is that most of the CPU time goes to the
kernel (darker blue) when linking with ThinLTO:
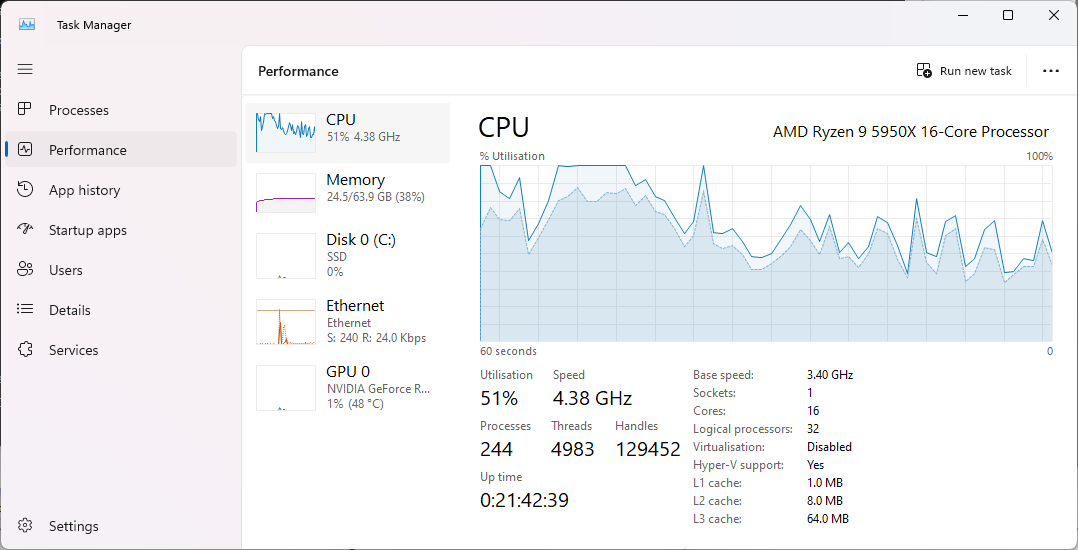
With this PR, most time is spent in user space (light blue):

On higher core count machines, before this PR, the CPU usage becomes
pretty much flat because of contention:
<img width="549" alt="VM_176_windows_heap"
src="https://github.com/llvm/llvm-project/assets/37383324/f27d5800-ee02-496d-a4e7-88177e0727f0">
With this PR, similarily most CPU time is now used:
<img width="549" alt="VM_176_with_rpmalloc"
src="https://github.com/llvm/llvm-project/assets/37383324/7d4785dd-94a7-4f06-9b16-aaa4e2e505c8">
### Changes in this PR
The avenue I've taken here is to vendor/re-licence rpmalloc in-tree, and
use it when building the Windows 64-bit release. Given the permissive
rpmalloc licence, prior discussions with the LLVM foundation and
@lattner suggested this vendoring. Rpmalloc's author (@mjansson) kindly
agreed to ~~donate~~ re-licence the rpmalloc code in LLVM (please do
correct me if I misinterpreted our past communications).
I've chosen rpmalloc because it's small and gives the best value
overall. The source code is only 4 .c files. Rpmalloc is statically
replacing the weak CRT alloc symbols at link time, and has no dynamic
patching like mimalloc. As an alternative, there were several
unsuccessfull attempts made by Russell Gallop to use SCUDO in the past,
please see thread in https://reviews.llvm.org/D86694. If later someone
comes up with a PR of similar performance that uses SCUDO, we could then
delete this vendored rpmalloc folder.
I've added a new cmake flag `LLVM_ENABLE_RPMALLOC` which essentialy sets
`LLVM_INTEGRATED_CRT_ALLOC` to the in-tree rpmalloc source.
### Performance
The most obvious test is profling a ThinLTO linking step with LLD. I've
used a Clang compilation as a testbed, ie.
```
set OPTS=/GS- /D_ITERATOR_DEBUG_LEVEL=0 -Xclang -O3 -fstrict-aliasing -march=native -flto=thin -fwhole-program-vtables -fuse-ld=lld
cmake -G Ninja %ROOT%/llvm -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_ASSERTIONS=TRUE -DLLVM_ENABLE_PROJECTS="clang" -DLLVM_ENABLE_PDB=ON -DLLVM_OPTIMIZED_TABLEGEN=ON -DCMAKE_C_COMPILER=clang-cl.exe -DCMAKE_CXX_COMPILER=clang-cl.exe -DCMAKE_LINKER=lld-link.exe -DLLVM_ENABLE_LLD=ON -DCMAKE_CXX_FLAGS="%OPTS%" -DCMAKE_C_FLAGS="%OPTS%" -DLLVM_ENABLE_LTO=THIN
```
I've profiled the linking step with no LTO cache, with Powershell, such
as:
```
Measure-Command { lld-link /nologo @CMakeFiles\clang.rsp /out:bin\clang.exe /implib:lib\clang.lib /pdb:bin\clang.pdb /version:0.0 /machine:x64 /STACK:10000000 /DEBUG /OPT:REF /OPT:ICF /INCREMENTAL:NO /subsystem:console /MANIFEST:EMBED,ID=1 }`
```
Timings:
| Machine | Allocator | Time to link |
|--------|--------|--------|
| 16c/32t AMD Ryzen 9 5950X | Windows Heap | 10 min 38 sec |
| | **Rpmalloc** | **4 min 11 sec** |
| 32c/64t AMD Ryzen Threadripper PRO 3975WX | Windows Heap | 23 min 29
sec |
| | **Rpmalloc** | **2 min 11 sec** |
| | **Rpmalloc + /threads:64** | **1 min 50 sec** |
| 176 vCPU (2 socket) Intel Xeon Platinium 8481C (fixed clock 2.7 GHz) |
Windows Heap | 43 min 40 sec |
| | **Rpmalloc** | **1 min 45 sec** |
This also improves the overall performance when building with clang-cl.
I've profiled a regular compilation of clang itself, ie:
```
set OPTS=/GS- /D_ITERATOR_DEBUG_LEVEL=0 /arch:AVX -fuse-ld=lld
cmake -G Ninja %ROOT%/llvm -DCMAKE_BUILD_TYPE=Release -DLLVM_ENABLE_ASSERTIONS=TRUE -DLLVM_ENABLE_PROJECTS="clang;lld" -DLLVM_ENABLE_PDB=ON -DLLVM_OPTIMIZED_TABLEGEN=ON -DCMAKE_C_COMPILER=clang-cl.exe -DCMAKE_CXX_COMPILER=clang-cl.exe -DCMAKE_LINKER=lld-link.exe -DLLVM_ENABLE_LLD=ON -DCMAKE_CXX_FLAGS="%OPTS%" -DCMAKE_C_FLAGS="%OPTS%"
```
This saves approx. 30 sec when building on the Threadripper PRO 3975WX:
```
(default Windows Heap)
C:\src\git\llvm-project>hyperfine -r 5 -p "make_llvm.bat stage1_test2" "ninja clang -C stage1_test2"
Benchmark 1: ninja clang -C stage1_test2
Time (mean ± σ): 392.716 s ± 3.830 s [User: 17734.025 s, System: 1078.674 s]
Range (min … max): 390.127 s … 399.449 s 5 runs
(rpmalloc)
C:\src\git\llvm-project>hyperfine -r 5 -p "make_llvm.bat stage1_test2" "ninja clang -C stage1_test2"
Benchmark 1: ninja clang -C stage1_test2
Time (mean ± σ): 360.824 s ± 1.162 s [User: 15148.637 s, System: 905.175 s]
Range (min … max): 359.208 s … 362.288 s 5 runs
```
3993 lines
144 KiB
C
3993 lines
144 KiB
C
//===---------------------- rpmalloc.c ------------------*- C -*-=============//
|
|
//
|
|
// Part of the LLVM Project, under the Apache License v2.0 with LLVM Exceptions.
|
|
// See https://llvm.org/LICENSE.txt for license information.
|
|
// SPDX-License-Identifier: Apache-2.0 WITH LLVM-exception
|
|
//
|
|
//===----------------------------------------------------------------------===//
|
|
//
|
|
// This library provides a cross-platform lock free thread caching malloc
|
|
// implementation in C11.
|
|
//
|
|
//===----------------------------------------------------------------------===//
|
|
|
|
#include "rpmalloc.h"
|
|
|
|
////////////
|
|
///
|
|
/// Build time configurable limits
|
|
///
|
|
//////
|
|
|
|
#if defined(__clang__)
|
|
#pragma clang diagnostic ignored "-Wunused-macros"
|
|
#pragma clang diagnostic ignored "-Wunused-function"
|
|
#if __has_warning("-Wreserved-identifier")
|
|
#pragma clang diagnostic ignored "-Wreserved-identifier"
|
|
#endif
|
|
#if __has_warning("-Wstatic-in-inline")
|
|
#pragma clang diagnostic ignored "-Wstatic-in-inline"
|
|
#endif
|
|
#elif defined(__GNUC__)
|
|
#pragma GCC diagnostic ignored "-Wunused-macros"
|
|
#pragma GCC diagnostic ignored "-Wunused-function"
|
|
#endif
|
|
|
|
#if !defined(__has_builtin)
|
|
#define __has_builtin(b) 0
|
|
#endif
|
|
|
|
#if defined(__GNUC__) || defined(__clang__)
|
|
|
|
#if __has_builtin(__builtin_memcpy_inline)
|
|
#define _rpmalloc_memcpy_const(x, y, s) __builtin_memcpy_inline(x, y, s)
|
|
#else
|
|
#define _rpmalloc_memcpy_const(x, y, s) \
|
|
do { \
|
|
_Static_assert(__builtin_choose_expr(__builtin_constant_p(s), 1, 0), \
|
|
"len must be a constant integer"); \
|
|
memcpy(x, y, s); \
|
|
} while (0)
|
|
#endif
|
|
|
|
#if __has_builtin(__builtin_memset_inline)
|
|
#define _rpmalloc_memset_const(x, y, s) __builtin_memset_inline(x, y, s)
|
|
#else
|
|
#define _rpmalloc_memset_const(x, y, s) \
|
|
do { \
|
|
_Static_assert(__builtin_choose_expr(__builtin_constant_p(s), 1, 0), \
|
|
"len must be a constant integer"); \
|
|
memset(x, y, s); \
|
|
} while (0)
|
|
#endif
|
|
#else
|
|
#define _rpmalloc_memcpy_const(x, y, s) memcpy(x, y, s)
|
|
#define _rpmalloc_memset_const(x, y, s) memset(x, y, s)
|
|
#endif
|
|
|
|
#if __has_builtin(__builtin_assume)
|
|
#define rpmalloc_assume(cond) __builtin_assume(cond)
|
|
#elif defined(__GNUC__)
|
|
#define rpmalloc_assume(cond) \
|
|
do { \
|
|
if (!__builtin_expect(cond, 0)) \
|
|
__builtin_unreachable(); \
|
|
} while (0)
|
|
#elif defined(_MSC_VER)
|
|
#define rpmalloc_assume(cond) __assume(cond)
|
|
#else
|
|
#define rpmalloc_assume(cond) 0
|
|
#endif
|
|
|
|
#ifndef HEAP_ARRAY_SIZE
|
|
//! Size of heap hashmap
|
|
#define HEAP_ARRAY_SIZE 47
|
|
#endif
|
|
#ifndef ENABLE_THREAD_CACHE
|
|
//! Enable per-thread cache
|
|
#define ENABLE_THREAD_CACHE 1
|
|
#endif
|
|
#ifndef ENABLE_GLOBAL_CACHE
|
|
//! Enable global cache shared between all threads, requires thread cache
|
|
#define ENABLE_GLOBAL_CACHE 1
|
|
#endif
|
|
#ifndef ENABLE_VALIDATE_ARGS
|
|
//! Enable validation of args to public entry points
|
|
#define ENABLE_VALIDATE_ARGS 0
|
|
#endif
|
|
#ifndef ENABLE_STATISTICS
|
|
//! Enable statistics collection
|
|
#define ENABLE_STATISTICS 0
|
|
#endif
|
|
#ifndef ENABLE_ASSERTS
|
|
//! Enable asserts
|
|
#define ENABLE_ASSERTS 0
|
|
#endif
|
|
#ifndef ENABLE_OVERRIDE
|
|
//! Override standard library malloc/free and new/delete entry points
|
|
#define ENABLE_OVERRIDE 0
|
|
#endif
|
|
#ifndef ENABLE_PRELOAD
|
|
//! Support preloading
|
|
#define ENABLE_PRELOAD 0
|
|
#endif
|
|
#ifndef DISABLE_UNMAP
|
|
//! Disable unmapping memory pages (also enables unlimited cache)
|
|
#define DISABLE_UNMAP 0
|
|
#endif
|
|
#ifndef ENABLE_UNLIMITED_CACHE
|
|
//! Enable unlimited global cache (no unmapping until finalization)
|
|
#define ENABLE_UNLIMITED_CACHE 0
|
|
#endif
|
|
#ifndef ENABLE_ADAPTIVE_THREAD_CACHE
|
|
//! Enable adaptive thread cache size based on use heuristics
|
|
#define ENABLE_ADAPTIVE_THREAD_CACHE 0
|
|
#endif
|
|
#ifndef DEFAULT_SPAN_MAP_COUNT
|
|
//! Default number of spans to map in call to map more virtual memory (default
|
|
//! values yield 4MiB here)
|
|
#define DEFAULT_SPAN_MAP_COUNT 64
|
|
#endif
|
|
#ifndef GLOBAL_CACHE_MULTIPLIER
|
|
//! Multiplier for global cache
|
|
#define GLOBAL_CACHE_MULTIPLIER 8
|
|
#endif
|
|
|
|
#if DISABLE_UNMAP && !ENABLE_GLOBAL_CACHE
|
|
#error Must use global cache if unmap is disabled
|
|
#endif
|
|
|
|
#if DISABLE_UNMAP
|
|
#undef ENABLE_UNLIMITED_CACHE
|
|
#define ENABLE_UNLIMITED_CACHE 1
|
|
#endif
|
|
|
|
#if !ENABLE_GLOBAL_CACHE
|
|
#undef ENABLE_UNLIMITED_CACHE
|
|
#define ENABLE_UNLIMITED_CACHE 0
|
|
#endif
|
|
|
|
#if !ENABLE_THREAD_CACHE
|
|
#undef ENABLE_ADAPTIVE_THREAD_CACHE
|
|
#define ENABLE_ADAPTIVE_THREAD_CACHE 0
|
|
#endif
|
|
|
|
#if defined(_WIN32) || defined(__WIN32__) || defined(_WIN64)
|
|
#define PLATFORM_WINDOWS 1
|
|
#define PLATFORM_POSIX 0
|
|
#else
|
|
#define PLATFORM_WINDOWS 0
|
|
#define PLATFORM_POSIX 1
|
|
#endif
|
|
|
|
/// Platform and arch specifics
|
|
#if defined(_MSC_VER) && !defined(__clang__)
|
|
#pragma warning(disable : 5105)
|
|
#ifndef FORCEINLINE
|
|
#define FORCEINLINE inline __forceinline
|
|
#endif
|
|
#define _Static_assert static_assert
|
|
#else
|
|
#ifndef FORCEINLINE
|
|
#define FORCEINLINE inline __attribute__((__always_inline__))
|
|
#endif
|
|
#endif
|
|
#if PLATFORM_WINDOWS
|
|
#ifndef WIN32_LEAN_AND_MEAN
|
|
#define WIN32_LEAN_AND_MEAN
|
|
#endif
|
|
#include <windows.h>
|
|
#if ENABLE_VALIDATE_ARGS
|
|
#include <intsafe.h>
|
|
#endif
|
|
#else
|
|
#include <stdio.h>
|
|
#include <stdlib.h>
|
|
#include <time.h>
|
|
#include <unistd.h>
|
|
#if defined(__linux__) || defined(__ANDROID__)
|
|
#include <sys/prctl.h>
|
|
#if !defined(PR_SET_VMA)
|
|
#define PR_SET_VMA 0x53564d41
|
|
#define PR_SET_VMA_ANON_NAME 0
|
|
#endif
|
|
#endif
|
|
#if defined(__APPLE__)
|
|
#include <TargetConditionals.h>
|
|
#if !TARGET_OS_IPHONE && !TARGET_OS_SIMULATOR
|
|
#include <mach/mach_vm.h>
|
|
#include <mach/vm_statistics.h>
|
|
#endif
|
|
#include <pthread.h>
|
|
#endif
|
|
#if defined(__HAIKU__) || defined(__TINYC__)
|
|
#include <pthread.h>
|
|
#endif
|
|
#endif
|
|
|
|
#include <errno.h>
|
|
#include <stdint.h>
|
|
#include <string.h>
|
|
|
|
#if defined(_WIN32) && (!defined(BUILD_DYNAMIC_LINK) || !BUILD_DYNAMIC_LINK)
|
|
#include <fibersapi.h>
|
|
static DWORD fls_key;
|
|
#endif
|
|
|
|
#if PLATFORM_POSIX
|
|
#include <sched.h>
|
|
#include <sys/mman.h>
|
|
#ifdef __FreeBSD__
|
|
#include <sys/sysctl.h>
|
|
#define MAP_HUGETLB MAP_ALIGNED_SUPER
|
|
#ifndef PROT_MAX
|
|
#define PROT_MAX(f) 0
|
|
#endif
|
|
#else
|
|
#define PROT_MAX(f) 0
|
|
#endif
|
|
#ifdef __sun
|
|
extern int madvise(caddr_t, size_t, int);
|
|
#endif
|
|
#ifndef MAP_UNINITIALIZED
|
|
#define MAP_UNINITIALIZED 0
|
|
#endif
|
|
#endif
|
|
#include <errno.h>
|
|
|
|
#if ENABLE_ASSERTS
|
|
#undef NDEBUG
|
|
#if defined(_MSC_VER) && !defined(_DEBUG)
|
|
#define _DEBUG
|
|
#endif
|
|
#include <assert.h>
|
|
#define RPMALLOC_TOSTRING_M(x) #x
|
|
#define RPMALLOC_TOSTRING(x) RPMALLOC_TOSTRING_M(x)
|
|
#define rpmalloc_assert(truth, message) \
|
|
do { \
|
|
if (!(truth)) { \
|
|
if (_memory_config.error_callback) { \
|
|
_memory_config.error_callback(message " (" RPMALLOC_TOSTRING( \
|
|
truth) ") at " __FILE__ ":" RPMALLOC_TOSTRING(__LINE__)); \
|
|
} else { \
|
|
assert((truth) && message); \
|
|
} \
|
|
} \
|
|
} while (0)
|
|
#else
|
|
#define rpmalloc_assert(truth, message) \
|
|
do { \
|
|
} while (0)
|
|
#endif
|
|
#if ENABLE_STATISTICS
|
|
#include <stdio.h>
|
|
#endif
|
|
|
|
//////
|
|
///
|
|
/// Atomic access abstraction (since MSVC does not do C11 yet)
|
|
///
|
|
//////
|
|
|
|
#if defined(_MSC_VER) && !defined(__clang__)
|
|
|
|
typedef volatile long atomic32_t;
|
|
typedef volatile long long atomic64_t;
|
|
typedef volatile void *atomicptr_t;
|
|
|
|
static FORCEINLINE int32_t atomic_load32(atomic32_t *src) { return *src; }
|
|
static FORCEINLINE void atomic_store32(atomic32_t *dst, int32_t val) {
|
|
*dst = val;
|
|
}
|
|
static FORCEINLINE int32_t atomic_incr32(atomic32_t *val) {
|
|
return (int32_t)InterlockedIncrement(val);
|
|
}
|
|
static FORCEINLINE int32_t atomic_decr32(atomic32_t *val) {
|
|
return (int32_t)InterlockedDecrement(val);
|
|
}
|
|
static FORCEINLINE int32_t atomic_add32(atomic32_t *val, int32_t add) {
|
|
return (int32_t)InterlockedExchangeAdd(val, add) + add;
|
|
}
|
|
static FORCEINLINE int atomic_cas32_acquire(atomic32_t *dst, int32_t val,
|
|
int32_t ref) {
|
|
return (InterlockedCompareExchange(dst, val, ref) == ref) ? 1 : 0;
|
|
}
|
|
static FORCEINLINE void atomic_store32_release(atomic32_t *dst, int32_t val) {
|
|
*dst = val;
|
|
}
|
|
static FORCEINLINE int64_t atomic_load64(atomic64_t *src) { return *src; }
|
|
static FORCEINLINE int64_t atomic_add64(atomic64_t *val, int64_t add) {
|
|
return (int64_t)InterlockedExchangeAdd64(val, add) + add;
|
|
}
|
|
static FORCEINLINE void *atomic_load_ptr(atomicptr_t *src) {
|
|
return (void *)*src;
|
|
}
|
|
static FORCEINLINE void atomic_store_ptr(atomicptr_t *dst, void *val) {
|
|
*dst = val;
|
|
}
|
|
static FORCEINLINE void atomic_store_ptr_release(atomicptr_t *dst, void *val) {
|
|
*dst = val;
|
|
}
|
|
static FORCEINLINE void *atomic_exchange_ptr_acquire(atomicptr_t *dst,
|
|
void *val) {
|
|
return (void *)InterlockedExchangePointer((void *volatile *)dst, val);
|
|
}
|
|
static FORCEINLINE int atomic_cas_ptr(atomicptr_t *dst, void *val, void *ref) {
|
|
return (InterlockedCompareExchangePointer((void *volatile *)dst, val, ref) ==
|
|
ref)
|
|
? 1
|
|
: 0;
|
|
}
|
|
|
|
#define EXPECTED(x) (x)
|
|
#define UNEXPECTED(x) (x)
|
|
|
|
#else
|
|
|
|
#include <stdatomic.h>
|
|
|
|
typedef volatile _Atomic(int32_t) atomic32_t;
|
|
typedef volatile _Atomic(int64_t) atomic64_t;
|
|
typedef volatile _Atomic(void *) atomicptr_t;
|
|
|
|
static FORCEINLINE int32_t atomic_load32(atomic32_t *src) {
|
|
return atomic_load_explicit(src, memory_order_relaxed);
|
|
}
|
|
static FORCEINLINE void atomic_store32(atomic32_t *dst, int32_t val) {
|
|
atomic_store_explicit(dst, val, memory_order_relaxed);
|
|
}
|
|
static FORCEINLINE int32_t atomic_incr32(atomic32_t *val) {
|
|
return atomic_fetch_add_explicit(val, 1, memory_order_relaxed) + 1;
|
|
}
|
|
static FORCEINLINE int32_t atomic_decr32(atomic32_t *val) {
|
|
return atomic_fetch_add_explicit(val, -1, memory_order_relaxed) - 1;
|
|
}
|
|
static FORCEINLINE int32_t atomic_add32(atomic32_t *val, int32_t add) {
|
|
return atomic_fetch_add_explicit(val, add, memory_order_relaxed) + add;
|
|
}
|
|
static FORCEINLINE int atomic_cas32_acquire(atomic32_t *dst, int32_t val,
|
|
int32_t ref) {
|
|
return atomic_compare_exchange_weak_explicit(
|
|
dst, &ref, val, memory_order_acquire, memory_order_relaxed);
|
|
}
|
|
static FORCEINLINE void atomic_store32_release(atomic32_t *dst, int32_t val) {
|
|
atomic_store_explicit(dst, val, memory_order_release);
|
|
}
|
|
static FORCEINLINE int64_t atomic_load64(atomic64_t *val) {
|
|
return atomic_load_explicit(val, memory_order_relaxed);
|
|
}
|
|
static FORCEINLINE int64_t atomic_add64(atomic64_t *val, int64_t add) {
|
|
return atomic_fetch_add_explicit(val, add, memory_order_relaxed) + add;
|
|
}
|
|
static FORCEINLINE void *atomic_load_ptr(atomicptr_t *src) {
|
|
return atomic_load_explicit(src, memory_order_relaxed);
|
|
}
|
|
static FORCEINLINE void atomic_store_ptr(atomicptr_t *dst, void *val) {
|
|
atomic_store_explicit(dst, val, memory_order_relaxed);
|
|
}
|
|
static FORCEINLINE void atomic_store_ptr_release(atomicptr_t *dst, void *val) {
|
|
atomic_store_explicit(dst, val, memory_order_release);
|
|
}
|
|
static FORCEINLINE void *atomic_exchange_ptr_acquire(atomicptr_t *dst,
|
|
void *val) {
|
|
return atomic_exchange_explicit(dst, val, memory_order_acquire);
|
|
}
|
|
static FORCEINLINE int atomic_cas_ptr(atomicptr_t *dst, void *val, void *ref) {
|
|
return atomic_compare_exchange_weak_explicit(
|
|
dst, &ref, val, memory_order_relaxed, memory_order_relaxed);
|
|
}
|
|
|
|
#define EXPECTED(x) __builtin_expect((x), 1)
|
|
#define UNEXPECTED(x) __builtin_expect((x), 0)
|
|
|
|
#endif
|
|
|
|
////////////
|
|
///
|
|
/// Statistics related functions (evaluate to nothing when statistics not
|
|
/// enabled)
|
|
///
|
|
//////
|
|
|
|
#if ENABLE_STATISTICS
|
|
#define _rpmalloc_stat_inc(counter) atomic_incr32(counter)
|
|
#define _rpmalloc_stat_dec(counter) atomic_decr32(counter)
|
|
#define _rpmalloc_stat_add(counter, value) \
|
|
atomic_add32(counter, (int32_t)(value))
|
|
#define _rpmalloc_stat_add64(counter, value) \
|
|
atomic_add64(counter, (int64_t)(value))
|
|
#define _rpmalloc_stat_add_peak(counter, value, peak) \
|
|
do { \
|
|
int32_t _cur_count = atomic_add32(counter, (int32_t)(value)); \
|
|
if (_cur_count > (peak)) \
|
|
peak = _cur_count; \
|
|
} while (0)
|
|
#define _rpmalloc_stat_sub(counter, value) \
|
|
atomic_add32(counter, -(int32_t)(value))
|
|
#define _rpmalloc_stat_inc_alloc(heap, class_idx) \
|
|
do { \
|
|
int32_t alloc_current = \
|
|
atomic_incr32(&heap->size_class_use[class_idx].alloc_current); \
|
|
if (alloc_current > heap->size_class_use[class_idx].alloc_peak) \
|
|
heap->size_class_use[class_idx].alloc_peak = alloc_current; \
|
|
atomic_incr32(&heap->size_class_use[class_idx].alloc_total); \
|
|
} while (0)
|
|
#define _rpmalloc_stat_inc_free(heap, class_idx) \
|
|
do { \
|
|
atomic_decr32(&heap->size_class_use[class_idx].alloc_current); \
|
|
atomic_incr32(&heap->size_class_use[class_idx].free_total); \
|
|
} while (0)
|
|
#else
|
|
#define _rpmalloc_stat_inc(counter) \
|
|
do { \
|
|
} while (0)
|
|
#define _rpmalloc_stat_dec(counter) \
|
|
do { \
|
|
} while (0)
|
|
#define _rpmalloc_stat_add(counter, value) \
|
|
do { \
|
|
} while (0)
|
|
#define _rpmalloc_stat_add64(counter, value) \
|
|
do { \
|
|
} while (0)
|
|
#define _rpmalloc_stat_add_peak(counter, value, peak) \
|
|
do { \
|
|
} while (0)
|
|
#define _rpmalloc_stat_sub(counter, value) \
|
|
do { \
|
|
} while (0)
|
|
#define _rpmalloc_stat_inc_alloc(heap, class_idx) \
|
|
do { \
|
|
} while (0)
|
|
#define _rpmalloc_stat_inc_free(heap, class_idx) \
|
|
do { \
|
|
} while (0)
|
|
#endif
|
|
|
|
///
|
|
/// Preconfigured limits and sizes
|
|
///
|
|
|
|
//! Granularity of a small allocation block (must be power of two)
|
|
#define SMALL_GRANULARITY 16
|
|
//! Small granularity shift count
|
|
#define SMALL_GRANULARITY_SHIFT 4
|
|
//! Number of small block size classes
|
|
#define SMALL_CLASS_COUNT 65
|
|
//! Maximum size of a small block
|
|
#define SMALL_SIZE_LIMIT (SMALL_GRANULARITY * (SMALL_CLASS_COUNT - 1))
|
|
//! Granularity of a medium allocation block
|
|
#define MEDIUM_GRANULARITY 512
|
|
//! Medium granularity shift count
|
|
#define MEDIUM_GRANULARITY_SHIFT 9
|
|
//! Number of medium block size classes
|
|
#define MEDIUM_CLASS_COUNT 61
|
|
//! Total number of small + medium size classes
|
|
#define SIZE_CLASS_COUNT (SMALL_CLASS_COUNT + MEDIUM_CLASS_COUNT)
|
|
//! Number of large block size classes
|
|
#define LARGE_CLASS_COUNT 63
|
|
//! Maximum size of a medium block
|
|
#define MEDIUM_SIZE_LIMIT \
|
|
(SMALL_SIZE_LIMIT + (MEDIUM_GRANULARITY * MEDIUM_CLASS_COUNT))
|
|
//! Maximum size of a large block
|
|
#define LARGE_SIZE_LIMIT \
|
|
((LARGE_CLASS_COUNT * _memory_span_size) - SPAN_HEADER_SIZE)
|
|
//! Size of a span header (must be a multiple of SMALL_GRANULARITY and a power
|
|
//! of two)
|
|
#define SPAN_HEADER_SIZE 128
|
|
//! Number of spans in thread cache
|
|
#define MAX_THREAD_SPAN_CACHE 400
|
|
//! Number of spans to transfer between thread and global cache
|
|
#define THREAD_SPAN_CACHE_TRANSFER 64
|
|
//! Number of spans in thread cache for large spans (must be greater than
|
|
//! LARGE_CLASS_COUNT / 2)
|
|
#define MAX_THREAD_SPAN_LARGE_CACHE 100
|
|
//! Number of spans to transfer between thread and global cache for large spans
|
|
#define THREAD_SPAN_LARGE_CACHE_TRANSFER 6
|
|
|
|
_Static_assert((SMALL_GRANULARITY & (SMALL_GRANULARITY - 1)) == 0,
|
|
"Small granularity must be power of two");
|
|
_Static_assert((SPAN_HEADER_SIZE & (SPAN_HEADER_SIZE - 1)) == 0,
|
|
"Span header size must be power of two");
|
|
|
|
#if ENABLE_VALIDATE_ARGS
|
|
//! Maximum allocation size to avoid integer overflow
|
|
#undef MAX_ALLOC_SIZE
|
|
#define MAX_ALLOC_SIZE (((size_t) - 1) - _memory_span_size)
|
|
#endif
|
|
|
|
#define pointer_offset(ptr, ofs) (void *)((char *)(ptr) + (ptrdiff_t)(ofs))
|
|
#define pointer_diff(first, second) \
|
|
(ptrdiff_t)((const char *)(first) - (const char *)(second))
|
|
|
|
#define INVALID_POINTER ((void *)((uintptr_t) - 1))
|
|
|
|
#define SIZE_CLASS_LARGE SIZE_CLASS_COUNT
|
|
#define SIZE_CLASS_HUGE ((uint32_t) - 1)
|
|
|
|
////////////
|
|
///
|
|
/// Data types
|
|
///
|
|
//////
|
|
|
|
//! A memory heap, per thread
|
|
typedef struct heap_t heap_t;
|
|
//! Span of memory pages
|
|
typedef struct span_t span_t;
|
|
//! Span list
|
|
typedef struct span_list_t span_list_t;
|
|
//! Span active data
|
|
typedef struct span_active_t span_active_t;
|
|
//! Size class definition
|
|
typedef struct size_class_t size_class_t;
|
|
//! Global cache
|
|
typedef struct global_cache_t global_cache_t;
|
|
|
|
//! Flag indicating span is the first (master) span of a split superspan
|
|
#define SPAN_FLAG_MASTER 1U
|
|
//! Flag indicating span is a secondary (sub) span of a split superspan
|
|
#define SPAN_FLAG_SUBSPAN 2U
|
|
//! Flag indicating span has blocks with increased alignment
|
|
#define SPAN_FLAG_ALIGNED_BLOCKS 4U
|
|
//! Flag indicating an unmapped master span
|
|
#define SPAN_FLAG_UNMAPPED_MASTER 8U
|
|
|
|
#if ENABLE_ADAPTIVE_THREAD_CACHE || ENABLE_STATISTICS
|
|
struct span_use_t {
|
|
//! Current number of spans used (actually used, not in cache)
|
|
atomic32_t current;
|
|
//! High water mark of spans used
|
|
atomic32_t high;
|
|
#if ENABLE_STATISTICS
|
|
//! Number of spans in deferred list
|
|
atomic32_t spans_deferred;
|
|
//! Number of spans transitioned to global cache
|
|
atomic32_t spans_to_global;
|
|
//! Number of spans transitioned from global cache
|
|
atomic32_t spans_from_global;
|
|
//! Number of spans transitioned to thread cache
|
|
atomic32_t spans_to_cache;
|
|
//! Number of spans transitioned from thread cache
|
|
atomic32_t spans_from_cache;
|
|
//! Number of spans transitioned to reserved state
|
|
atomic32_t spans_to_reserved;
|
|
//! Number of spans transitioned from reserved state
|
|
atomic32_t spans_from_reserved;
|
|
//! Number of raw memory map calls
|
|
atomic32_t spans_map_calls;
|
|
#endif
|
|
};
|
|
typedef struct span_use_t span_use_t;
|
|
#endif
|
|
|
|
#if ENABLE_STATISTICS
|
|
struct size_class_use_t {
|
|
//! Current number of allocations
|
|
atomic32_t alloc_current;
|
|
//! Peak number of allocations
|
|
int32_t alloc_peak;
|
|
//! Total number of allocations
|
|
atomic32_t alloc_total;
|
|
//! Total number of frees
|
|
atomic32_t free_total;
|
|
//! Number of spans in use
|
|
atomic32_t spans_current;
|
|
//! Number of spans transitioned to cache
|
|
int32_t spans_peak;
|
|
//! Number of spans transitioned to cache
|
|
atomic32_t spans_to_cache;
|
|
//! Number of spans transitioned from cache
|
|
atomic32_t spans_from_cache;
|
|
//! Number of spans transitioned from reserved state
|
|
atomic32_t spans_from_reserved;
|
|
//! Number of spans mapped
|
|
atomic32_t spans_map_calls;
|
|
int32_t unused;
|
|
};
|
|
typedef struct size_class_use_t size_class_use_t;
|
|
#endif
|
|
|
|
// A span can either represent a single span of memory pages with size declared
|
|
// by span_map_count configuration variable, or a set of spans in a continuous
|
|
// region, a super span. Any reference to the term "span" usually refers to both
|
|
// a single span or a super span. A super span can further be divided into
|
|
// multiple spans (or this, super spans), where the first (super)span is the
|
|
// master and subsequent (super)spans are subspans. The master span keeps track
|
|
// of how many subspans that are still alive and mapped in virtual memory, and
|
|
// once all subspans and master have been unmapped the entire superspan region
|
|
// is released and unmapped (on Windows for example, the entire superspan range
|
|
// has to be released in the same call to release the virtual memory range, but
|
|
// individual subranges can be decommitted individually to reduce physical
|
|
// memory use).
|
|
struct span_t {
|
|
//! Free list
|
|
void *free_list;
|
|
//! Total block count of size class
|
|
uint32_t block_count;
|
|
//! Size class
|
|
uint32_t size_class;
|
|
//! Index of last block initialized in free list
|
|
uint32_t free_list_limit;
|
|
//! Number of used blocks remaining when in partial state
|
|
uint32_t used_count;
|
|
//! Deferred free list
|
|
atomicptr_t free_list_deferred;
|
|
//! Size of deferred free list, or list of spans when part of a cache list
|
|
uint32_t list_size;
|
|
//! Size of a block
|
|
uint32_t block_size;
|
|
//! Flags and counters
|
|
uint32_t flags;
|
|
//! Number of spans
|
|
uint32_t span_count;
|
|
//! Total span counter for master spans
|
|
uint32_t total_spans;
|
|
//! Offset from master span for subspans
|
|
uint32_t offset_from_master;
|
|
//! Remaining span counter, for master spans
|
|
atomic32_t remaining_spans;
|
|
//! Alignment offset
|
|
uint32_t align_offset;
|
|
//! Owning heap
|
|
heap_t *heap;
|
|
//! Next span
|
|
span_t *next;
|
|
//! Previous span
|
|
span_t *prev;
|
|
};
|
|
_Static_assert(sizeof(span_t) <= SPAN_HEADER_SIZE, "span size mismatch");
|
|
|
|
struct span_cache_t {
|
|
size_t count;
|
|
span_t *span[MAX_THREAD_SPAN_CACHE];
|
|
};
|
|
typedef struct span_cache_t span_cache_t;
|
|
|
|
struct span_large_cache_t {
|
|
size_t count;
|
|
span_t *span[MAX_THREAD_SPAN_LARGE_CACHE];
|
|
};
|
|
typedef struct span_large_cache_t span_large_cache_t;
|
|
|
|
struct heap_size_class_t {
|
|
//! Free list of active span
|
|
void *free_list;
|
|
//! Double linked list of partially used spans with free blocks.
|
|
// Previous span pointer in head points to tail span of list.
|
|
span_t *partial_span;
|
|
//! Early level cache of fully free spans
|
|
span_t *cache;
|
|
};
|
|
typedef struct heap_size_class_t heap_size_class_t;
|
|
|
|
// Control structure for a heap, either a thread heap or a first class heap if
|
|
// enabled
|
|
struct heap_t {
|
|
//! Owning thread ID
|
|
uintptr_t owner_thread;
|
|
//! Free lists for each size class
|
|
heap_size_class_t size_class[SIZE_CLASS_COUNT];
|
|
#if ENABLE_THREAD_CACHE
|
|
//! Arrays of fully freed spans, single span
|
|
span_cache_t span_cache;
|
|
#endif
|
|
//! List of deferred free spans (single linked list)
|
|
atomicptr_t span_free_deferred;
|
|
//! Number of full spans
|
|
size_t full_span_count;
|
|
//! Mapped but unused spans
|
|
span_t *span_reserve;
|
|
//! Master span for mapped but unused spans
|
|
span_t *span_reserve_master;
|
|
//! Number of mapped but unused spans
|
|
uint32_t spans_reserved;
|
|
//! Child count
|
|
atomic32_t child_count;
|
|
//! Next heap in id list
|
|
heap_t *next_heap;
|
|
//! Next heap in orphan list
|
|
heap_t *next_orphan;
|
|
//! Heap ID
|
|
int32_t id;
|
|
//! Finalization state flag
|
|
int finalize;
|
|
//! Master heap owning the memory pages
|
|
heap_t *master_heap;
|
|
#if ENABLE_THREAD_CACHE
|
|
//! Arrays of fully freed spans, large spans with > 1 span count
|
|
span_large_cache_t span_large_cache[LARGE_CLASS_COUNT - 1];
|
|
#endif
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
//! Double linked list of fully utilized spans with free blocks for each size
|
|
//! class.
|
|
// Previous span pointer in head points to tail span of list.
|
|
span_t *full_span[SIZE_CLASS_COUNT];
|
|
//! Double linked list of large and huge spans allocated by this heap
|
|
span_t *large_huge_span;
|
|
#endif
|
|
#if ENABLE_ADAPTIVE_THREAD_CACHE || ENABLE_STATISTICS
|
|
//! Current and high water mark of spans used per span count
|
|
span_use_t span_use[LARGE_CLASS_COUNT];
|
|
#endif
|
|
#if ENABLE_STATISTICS
|
|
//! Allocation stats per size class
|
|
size_class_use_t size_class_use[SIZE_CLASS_COUNT + 1];
|
|
//! Number of bytes transitioned thread -> global
|
|
atomic64_t thread_to_global;
|
|
//! Number of bytes transitioned global -> thread
|
|
atomic64_t global_to_thread;
|
|
#endif
|
|
};
|
|
|
|
// Size class for defining a block size bucket
|
|
struct size_class_t {
|
|
//! Size of blocks in this class
|
|
uint32_t block_size;
|
|
//! Number of blocks in each chunk
|
|
uint16_t block_count;
|
|
//! Class index this class is merged with
|
|
uint16_t class_idx;
|
|
};
|
|
_Static_assert(sizeof(size_class_t) == 8, "Size class size mismatch");
|
|
|
|
struct global_cache_t {
|
|
//! Cache lock
|
|
atomic32_t lock;
|
|
//! Cache count
|
|
uint32_t count;
|
|
#if ENABLE_STATISTICS
|
|
//! Insert count
|
|
size_t insert_count;
|
|
//! Extract count
|
|
size_t extract_count;
|
|
#endif
|
|
//! Cached spans
|
|
span_t *span[GLOBAL_CACHE_MULTIPLIER * MAX_THREAD_SPAN_CACHE];
|
|
//! Unlimited cache overflow
|
|
span_t *overflow;
|
|
};
|
|
|
|
////////////
|
|
///
|
|
/// Global data
|
|
///
|
|
//////
|
|
|
|
//! Default span size (64KiB)
|
|
#define _memory_default_span_size (64 * 1024)
|
|
#define _memory_default_span_size_shift 16
|
|
#define _memory_default_span_mask (~((uintptr_t)(_memory_span_size - 1)))
|
|
|
|
//! Initialized flag
|
|
static int _rpmalloc_initialized;
|
|
//! Main thread ID
|
|
static uintptr_t _rpmalloc_main_thread_id;
|
|
//! Configuration
|
|
static rpmalloc_config_t _memory_config;
|
|
//! Memory page size
|
|
static size_t _memory_page_size;
|
|
//! Shift to divide by page size
|
|
static size_t _memory_page_size_shift;
|
|
//! Granularity at which memory pages are mapped by OS
|
|
static size_t _memory_map_granularity;
|
|
#if RPMALLOC_CONFIGURABLE
|
|
//! Size of a span of memory pages
|
|
static size_t _memory_span_size;
|
|
//! Shift to divide by span size
|
|
static size_t _memory_span_size_shift;
|
|
//! Mask to get to start of a memory span
|
|
static uintptr_t _memory_span_mask;
|
|
#else
|
|
//! Hardwired span size
|
|
#define _memory_span_size _memory_default_span_size
|
|
#define _memory_span_size_shift _memory_default_span_size_shift
|
|
#define _memory_span_mask _memory_default_span_mask
|
|
#endif
|
|
//! Number of spans to map in each map call
|
|
static size_t _memory_span_map_count;
|
|
//! Number of spans to keep reserved in each heap
|
|
static size_t _memory_heap_reserve_count;
|
|
//! Global size classes
|
|
static size_class_t _memory_size_class[SIZE_CLASS_COUNT];
|
|
//! Run-time size limit of medium blocks
|
|
static size_t _memory_medium_size_limit;
|
|
//! Heap ID counter
|
|
static atomic32_t _memory_heap_id;
|
|
//! Huge page support
|
|
static int _memory_huge_pages;
|
|
#if ENABLE_GLOBAL_CACHE
|
|
//! Global span cache
|
|
static global_cache_t _memory_span_cache[LARGE_CLASS_COUNT];
|
|
#endif
|
|
//! Global reserved spans
|
|
static span_t *_memory_global_reserve;
|
|
//! Global reserved count
|
|
static size_t _memory_global_reserve_count;
|
|
//! Global reserved master
|
|
static span_t *_memory_global_reserve_master;
|
|
//! All heaps
|
|
static heap_t *_memory_heaps[HEAP_ARRAY_SIZE];
|
|
//! Used to restrict access to mapping memory for huge pages
|
|
static atomic32_t _memory_global_lock;
|
|
//! Orphaned heaps
|
|
static heap_t *_memory_orphan_heaps;
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
//! Orphaned heaps (first class heaps)
|
|
static heap_t *_memory_first_class_orphan_heaps;
|
|
#endif
|
|
#if ENABLE_STATISTICS
|
|
//! Allocations counter
|
|
static atomic64_t _allocation_counter;
|
|
//! Deallocations counter
|
|
static atomic64_t _deallocation_counter;
|
|
//! Active heap count
|
|
static atomic32_t _memory_active_heaps;
|
|
//! Number of currently mapped memory pages
|
|
static atomic32_t _mapped_pages;
|
|
//! Peak number of concurrently mapped memory pages
|
|
static int32_t _mapped_pages_peak;
|
|
//! Number of mapped master spans
|
|
static atomic32_t _master_spans;
|
|
//! Number of unmapped dangling master spans
|
|
static atomic32_t _unmapped_master_spans;
|
|
//! Running counter of total number of mapped memory pages since start
|
|
static atomic32_t _mapped_total;
|
|
//! Running counter of total number of unmapped memory pages since start
|
|
static atomic32_t _unmapped_total;
|
|
//! Number of currently mapped memory pages in OS calls
|
|
static atomic32_t _mapped_pages_os;
|
|
//! Number of currently allocated pages in huge allocations
|
|
static atomic32_t _huge_pages_current;
|
|
//! Peak number of currently allocated pages in huge allocations
|
|
static int32_t _huge_pages_peak;
|
|
#endif
|
|
|
|
////////////
|
|
///
|
|
/// Thread local heap and ID
|
|
///
|
|
//////
|
|
|
|
//! Current thread heap
|
|
#if ((defined(__APPLE__) || defined(__HAIKU__)) && ENABLE_PRELOAD) || \
|
|
defined(__TINYC__)
|
|
static pthread_key_t _memory_thread_heap;
|
|
#else
|
|
#ifdef _MSC_VER
|
|
#define _Thread_local __declspec(thread)
|
|
#define TLS_MODEL
|
|
#else
|
|
#ifndef __HAIKU__
|
|
#define TLS_MODEL __attribute__((tls_model("initial-exec")))
|
|
#else
|
|
#define TLS_MODEL
|
|
#endif
|
|
#if !defined(__clang__) && defined(__GNUC__)
|
|
#define _Thread_local __thread
|
|
#endif
|
|
#endif
|
|
static _Thread_local heap_t *_memory_thread_heap TLS_MODEL;
|
|
#endif
|
|
|
|
static inline heap_t *get_thread_heap_raw(void) {
|
|
#if (defined(__APPLE__) || defined(__HAIKU__)) && ENABLE_PRELOAD
|
|
return pthread_getspecific(_memory_thread_heap);
|
|
#else
|
|
return _memory_thread_heap;
|
|
#endif
|
|
}
|
|
|
|
//! Get the current thread heap
|
|
static inline heap_t *get_thread_heap(void) {
|
|
heap_t *heap = get_thread_heap_raw();
|
|
#if ENABLE_PRELOAD
|
|
if (EXPECTED(heap != 0))
|
|
return heap;
|
|
rpmalloc_initialize();
|
|
return get_thread_heap_raw();
|
|
#else
|
|
return heap;
|
|
#endif
|
|
}
|
|
|
|
//! Fast thread ID
|
|
static inline uintptr_t get_thread_id(void) {
|
|
#if defined(_WIN32)
|
|
return (uintptr_t)((void *)NtCurrentTeb());
|
|
#elif (defined(__GNUC__) || defined(__clang__)) && !defined(__CYGWIN__)
|
|
uintptr_t tid;
|
|
#if defined(__i386__)
|
|
__asm__("movl %%gs:0, %0" : "=r"(tid) : :);
|
|
#elif defined(__x86_64__)
|
|
#if defined(__MACH__)
|
|
__asm__("movq %%gs:0, %0" : "=r"(tid) : :);
|
|
#else
|
|
__asm__("movq %%fs:0, %0" : "=r"(tid) : :);
|
|
#endif
|
|
#elif defined(__arm__)
|
|
__asm__ volatile("mrc p15, 0, %0, c13, c0, 3" : "=r"(tid));
|
|
#elif defined(__aarch64__)
|
|
#if defined(__MACH__)
|
|
// tpidr_el0 likely unused, always return 0 on iOS
|
|
__asm__ volatile("mrs %0, tpidrro_el0" : "=r"(tid));
|
|
#else
|
|
__asm__ volatile("mrs %0, tpidr_el0" : "=r"(tid));
|
|
#endif
|
|
#else
|
|
#error This platform needs implementation of get_thread_id()
|
|
#endif
|
|
return tid;
|
|
#else
|
|
#error This platform needs implementation of get_thread_id()
|
|
#endif
|
|
}
|
|
|
|
//! Set the current thread heap
|
|
static void set_thread_heap(heap_t *heap) {
|
|
#if ((defined(__APPLE__) || defined(__HAIKU__)) && ENABLE_PRELOAD) || \
|
|
defined(__TINYC__)
|
|
pthread_setspecific(_memory_thread_heap, heap);
|
|
#else
|
|
_memory_thread_heap = heap;
|
|
#endif
|
|
if (heap)
|
|
heap->owner_thread = get_thread_id();
|
|
}
|
|
|
|
//! Set main thread ID
|
|
extern void rpmalloc_set_main_thread(void);
|
|
|
|
void rpmalloc_set_main_thread(void) {
|
|
_rpmalloc_main_thread_id = get_thread_id();
|
|
}
|
|
|
|
static void _rpmalloc_spin(void) {
|
|
#if defined(_MSC_VER)
|
|
#if defined(_M_ARM64)
|
|
__yield();
|
|
#else
|
|
_mm_pause();
|
|
#endif
|
|
#elif defined(__x86_64__) || defined(__i386__)
|
|
__asm__ volatile("pause" ::: "memory");
|
|
#elif defined(__aarch64__) || (defined(__arm__) && __ARM_ARCH >= 7)
|
|
__asm__ volatile("yield" ::: "memory");
|
|
#elif defined(__powerpc__) || defined(__powerpc64__)
|
|
// No idea if ever been compiled in such archs but ... as precaution
|
|
__asm__ volatile("or 27,27,27");
|
|
#elif defined(__sparc__)
|
|
__asm__ volatile("rd %ccr, %g0 \n\trd %ccr, %g0 \n\trd %ccr, %g0");
|
|
#else
|
|
struct timespec ts = {0};
|
|
nanosleep(&ts, 0);
|
|
#endif
|
|
}
|
|
|
|
#if defined(_WIN32) && (!defined(BUILD_DYNAMIC_LINK) || !BUILD_DYNAMIC_LINK)
|
|
static void NTAPI _rpmalloc_thread_destructor(void *value) {
|
|
#if ENABLE_OVERRIDE
|
|
// If this is called on main thread it means rpmalloc_finalize
|
|
// has not been called and shutdown is forced (through _exit) or unclean
|
|
if (get_thread_id() == _rpmalloc_main_thread_id)
|
|
return;
|
|
#endif
|
|
if (value)
|
|
rpmalloc_thread_finalize(1);
|
|
}
|
|
#endif
|
|
|
|
////////////
|
|
///
|
|
/// Low level memory map/unmap
|
|
///
|
|
//////
|
|
|
|
static void _rpmalloc_set_name(void *address, size_t size) {
|
|
#if defined(__linux__) || defined(__ANDROID__)
|
|
const char *name = _memory_huge_pages ? _memory_config.huge_page_name
|
|
: _memory_config.page_name;
|
|
if (address == MAP_FAILED || !name)
|
|
return;
|
|
// If the kernel does not support CONFIG_ANON_VMA_NAME or if the call fails
|
|
// (e.g. invalid name) it is a no-op basically.
|
|
(void)prctl(PR_SET_VMA, PR_SET_VMA_ANON_NAME, (uintptr_t)address, size,
|
|
(uintptr_t)name);
|
|
#else
|
|
(void)sizeof(size);
|
|
(void)sizeof(address);
|
|
#endif
|
|
}
|
|
|
|
//! Map more virtual memory
|
|
// size is number of bytes to map
|
|
// offset receives the offset in bytes from start of mapped region
|
|
// returns address to start of mapped region to use
|
|
static void *_rpmalloc_mmap(size_t size, size_t *offset) {
|
|
rpmalloc_assert(!(size % _memory_page_size), "Invalid mmap size");
|
|
rpmalloc_assert(size >= _memory_page_size, "Invalid mmap size");
|
|
void *address = _memory_config.memory_map(size, offset);
|
|
if (EXPECTED(address != 0)) {
|
|
_rpmalloc_stat_add_peak(&_mapped_pages, (size >> _memory_page_size_shift),
|
|
_mapped_pages_peak);
|
|
_rpmalloc_stat_add(&_mapped_total, (size >> _memory_page_size_shift));
|
|
}
|
|
return address;
|
|
}
|
|
|
|
//! Unmap virtual memory
|
|
// address is the memory address to unmap, as returned from _memory_map
|
|
// size is the number of bytes to unmap, which might be less than full region
|
|
// for a partial unmap offset is the offset in bytes to the actual mapped
|
|
// region, as set by _memory_map release is set to 0 for partial unmap, or size
|
|
// of entire range for a full unmap
|
|
static void _rpmalloc_unmap(void *address, size_t size, size_t offset,
|
|
size_t release) {
|
|
rpmalloc_assert(!release || (release >= size), "Invalid unmap size");
|
|
rpmalloc_assert(!release || (release >= _memory_page_size),
|
|
"Invalid unmap size");
|
|
if (release) {
|
|
rpmalloc_assert(!(release % _memory_page_size), "Invalid unmap size");
|
|
_rpmalloc_stat_sub(&_mapped_pages, (release >> _memory_page_size_shift));
|
|
_rpmalloc_stat_add(&_unmapped_total, (release >> _memory_page_size_shift));
|
|
}
|
|
_memory_config.memory_unmap(address, size, offset, release);
|
|
}
|
|
|
|
//! Default implementation to map new pages to virtual memory
|
|
static void *_rpmalloc_mmap_os(size_t size, size_t *offset) {
|
|
// Either size is a heap (a single page) or a (multiple) span - we only need
|
|
// to align spans, and only if larger than map granularity
|
|
size_t padding = ((size >= _memory_span_size) &&
|
|
(_memory_span_size > _memory_map_granularity))
|
|
? _memory_span_size
|
|
: 0;
|
|
rpmalloc_assert(size >= _memory_page_size, "Invalid mmap size");
|
|
#if PLATFORM_WINDOWS
|
|
// Ok to MEM_COMMIT - according to MSDN, "actual physical pages are not
|
|
// allocated unless/until the virtual addresses are actually accessed"
|
|
void *ptr = VirtualAlloc(0, size + padding,
|
|
(_memory_huge_pages ? MEM_LARGE_PAGES : 0) |
|
|
MEM_RESERVE | MEM_COMMIT,
|
|
PAGE_READWRITE);
|
|
if (!ptr) {
|
|
if (_memory_config.map_fail_callback) {
|
|
if (_memory_config.map_fail_callback(size + padding))
|
|
return _rpmalloc_mmap_os(size, offset);
|
|
} else {
|
|
rpmalloc_assert(ptr, "Failed to map virtual memory block");
|
|
}
|
|
return 0;
|
|
}
|
|
#else
|
|
int flags = MAP_PRIVATE | MAP_ANONYMOUS | MAP_UNINITIALIZED;
|
|
#if defined(__APPLE__) && !TARGET_OS_IPHONE && !TARGET_OS_SIMULATOR
|
|
int fd = (int)VM_MAKE_TAG(240U);
|
|
if (_memory_huge_pages)
|
|
fd |= VM_FLAGS_SUPERPAGE_SIZE_2MB;
|
|
void *ptr = mmap(0, size + padding, PROT_READ | PROT_WRITE, flags, fd, 0);
|
|
#elif defined(MAP_HUGETLB)
|
|
void *ptr = mmap(0, size + padding,
|
|
PROT_READ | PROT_WRITE | PROT_MAX(PROT_READ | PROT_WRITE),
|
|
(_memory_huge_pages ? MAP_HUGETLB : 0) | flags, -1, 0);
|
|
#if defined(MADV_HUGEPAGE)
|
|
// In some configurations, huge pages allocations might fail thus
|
|
// we fallback to normal allocations and promote the region as transparent
|
|
// huge page
|
|
if ((ptr == MAP_FAILED || !ptr) && _memory_huge_pages) {
|
|
ptr = mmap(0, size + padding, PROT_READ | PROT_WRITE, flags, -1, 0);
|
|
if (ptr && ptr != MAP_FAILED) {
|
|
int prm = madvise(ptr, size + padding, MADV_HUGEPAGE);
|
|
(void)prm;
|
|
rpmalloc_assert((prm == 0), "Failed to promote the page to THP");
|
|
}
|
|
}
|
|
#endif
|
|
_rpmalloc_set_name(ptr, size + padding);
|
|
#elif defined(MAP_ALIGNED)
|
|
const size_t align =
|
|
(sizeof(size_t) * 8) - (size_t)(__builtin_clzl(size - 1));
|
|
void *ptr =
|
|
mmap(0, size + padding, PROT_READ | PROT_WRITE,
|
|
(_memory_huge_pages ? MAP_ALIGNED(align) : 0) | flags, -1, 0);
|
|
#elif defined(MAP_ALIGN)
|
|
caddr_t base = (_memory_huge_pages ? (caddr_t)(4 << 20) : 0);
|
|
void *ptr = mmap(base, size + padding, PROT_READ | PROT_WRITE,
|
|
(_memory_huge_pages ? MAP_ALIGN : 0) | flags, -1, 0);
|
|
#else
|
|
void *ptr = mmap(0, size + padding, PROT_READ | PROT_WRITE, flags, -1, 0);
|
|
#endif
|
|
if ((ptr == MAP_FAILED) || !ptr) {
|
|
if (_memory_config.map_fail_callback) {
|
|
if (_memory_config.map_fail_callback(size + padding))
|
|
return _rpmalloc_mmap_os(size, offset);
|
|
} else if (errno != ENOMEM) {
|
|
rpmalloc_assert((ptr != MAP_FAILED) && ptr,
|
|
"Failed to map virtual memory block");
|
|
}
|
|
return 0;
|
|
}
|
|
#endif
|
|
_rpmalloc_stat_add(&_mapped_pages_os,
|
|
(int32_t)((size + padding) >> _memory_page_size_shift));
|
|
if (padding) {
|
|
size_t final_padding = padding - ((uintptr_t)ptr & ~_memory_span_mask);
|
|
rpmalloc_assert(final_padding <= _memory_span_size,
|
|
"Internal failure in padding");
|
|
rpmalloc_assert(final_padding <= padding, "Internal failure in padding");
|
|
rpmalloc_assert(!(final_padding % 8), "Internal failure in padding");
|
|
ptr = pointer_offset(ptr, final_padding);
|
|
*offset = final_padding >> 3;
|
|
}
|
|
rpmalloc_assert((size < _memory_span_size) ||
|
|
!((uintptr_t)ptr & ~_memory_span_mask),
|
|
"Internal failure in padding");
|
|
return ptr;
|
|
}
|
|
|
|
//! Default implementation to unmap pages from virtual memory
|
|
static void _rpmalloc_unmap_os(void *address, size_t size, size_t offset,
|
|
size_t release) {
|
|
rpmalloc_assert(release || (offset == 0), "Invalid unmap size");
|
|
rpmalloc_assert(!release || (release >= _memory_page_size),
|
|
"Invalid unmap size");
|
|
rpmalloc_assert(size >= _memory_page_size, "Invalid unmap size");
|
|
if (release && offset) {
|
|
offset <<= 3;
|
|
address = pointer_offset(address, -(int32_t)offset);
|
|
if ((release >= _memory_span_size) &&
|
|
(_memory_span_size > _memory_map_granularity)) {
|
|
// Padding is always one span size
|
|
release += _memory_span_size;
|
|
}
|
|
}
|
|
#if !DISABLE_UNMAP
|
|
#if PLATFORM_WINDOWS
|
|
if (!VirtualFree(address, release ? 0 : size,
|
|
release ? MEM_RELEASE : MEM_DECOMMIT)) {
|
|
rpmalloc_assert(0, "Failed to unmap virtual memory block");
|
|
}
|
|
#else
|
|
if (release) {
|
|
if (munmap(address, release)) {
|
|
rpmalloc_assert(0, "Failed to unmap virtual memory block");
|
|
}
|
|
} else {
|
|
#if defined(MADV_FREE_REUSABLE)
|
|
int ret;
|
|
while ((ret = madvise(address, size, MADV_FREE_REUSABLE)) == -1 &&
|
|
(errno == EAGAIN))
|
|
errno = 0;
|
|
if ((ret == -1) && (errno != 0)) {
|
|
#elif defined(MADV_DONTNEED)
|
|
if (madvise(address, size, MADV_DONTNEED)) {
|
|
#elif defined(MADV_PAGEOUT)
|
|
if (madvise(address, size, MADV_PAGEOUT)) {
|
|
#elif defined(MADV_FREE)
|
|
if (madvise(address, size, MADV_FREE)) {
|
|
#else
|
|
if (posix_madvise(address, size, POSIX_MADV_DONTNEED)) {
|
|
#endif
|
|
rpmalloc_assert(0, "Failed to madvise virtual memory block as free");
|
|
}
|
|
}
|
|
#endif
|
|
#endif
|
|
if (release)
|
|
_rpmalloc_stat_sub(&_mapped_pages_os, release >> _memory_page_size_shift);
|
|
}
|
|
|
|
static void _rpmalloc_span_mark_as_subspan_unless_master(span_t *master,
|
|
span_t *subspan,
|
|
size_t span_count);
|
|
|
|
//! Use global reserved spans to fulfill a memory map request (reserve size must
|
|
//! be checked by caller)
|
|
static span_t *_rpmalloc_global_get_reserved_spans(size_t span_count) {
|
|
span_t *span = _memory_global_reserve;
|
|
_rpmalloc_span_mark_as_subspan_unless_master(_memory_global_reserve_master,
|
|
span, span_count);
|
|
_memory_global_reserve_count -= span_count;
|
|
if (_memory_global_reserve_count)
|
|
_memory_global_reserve =
|
|
(span_t *)pointer_offset(span, span_count << _memory_span_size_shift);
|
|
else
|
|
_memory_global_reserve = 0;
|
|
return span;
|
|
}
|
|
|
|
//! Store the given spans as global reserve (must only be called from within new
|
|
//! heap allocation, not thread safe)
|
|
static void _rpmalloc_global_set_reserved_spans(span_t *master, span_t *reserve,
|
|
size_t reserve_span_count) {
|
|
_memory_global_reserve_master = master;
|
|
_memory_global_reserve_count = reserve_span_count;
|
|
_memory_global_reserve = reserve;
|
|
}
|
|
|
|
////////////
|
|
///
|
|
/// Span linked list management
|
|
///
|
|
//////
|
|
|
|
//! Add a span to double linked list at the head
|
|
static void _rpmalloc_span_double_link_list_add(span_t **head, span_t *span) {
|
|
if (*head)
|
|
(*head)->prev = span;
|
|
span->next = *head;
|
|
*head = span;
|
|
}
|
|
|
|
//! Pop head span from double linked list
|
|
static void _rpmalloc_span_double_link_list_pop_head(span_t **head,
|
|
span_t *span) {
|
|
rpmalloc_assert(*head == span, "Linked list corrupted");
|
|
span = *head;
|
|
*head = span->next;
|
|
}
|
|
|
|
//! Remove a span from double linked list
|
|
static void _rpmalloc_span_double_link_list_remove(span_t **head,
|
|
span_t *span) {
|
|
rpmalloc_assert(*head, "Linked list corrupted");
|
|
if (*head == span) {
|
|
*head = span->next;
|
|
} else {
|
|
span_t *next_span = span->next;
|
|
span_t *prev_span = span->prev;
|
|
prev_span->next = next_span;
|
|
if (EXPECTED(next_span != 0))
|
|
next_span->prev = prev_span;
|
|
}
|
|
}
|
|
|
|
////////////
|
|
///
|
|
/// Span control
|
|
///
|
|
//////
|
|
|
|
static void _rpmalloc_heap_cache_insert(heap_t *heap, span_t *span);
|
|
|
|
static void _rpmalloc_heap_finalize(heap_t *heap);
|
|
|
|
static void _rpmalloc_heap_set_reserved_spans(heap_t *heap, span_t *master,
|
|
span_t *reserve,
|
|
size_t reserve_span_count);
|
|
|
|
//! Declare the span to be a subspan and store distance from master span and
|
|
//! span count
|
|
static void _rpmalloc_span_mark_as_subspan_unless_master(span_t *master,
|
|
span_t *subspan,
|
|
size_t span_count) {
|
|
rpmalloc_assert((subspan != master) || (subspan->flags & SPAN_FLAG_MASTER),
|
|
"Span master pointer and/or flag mismatch");
|
|
if (subspan != master) {
|
|
subspan->flags = SPAN_FLAG_SUBSPAN;
|
|
subspan->offset_from_master =
|
|
(uint32_t)((uintptr_t)pointer_diff(subspan, master) >>
|
|
_memory_span_size_shift);
|
|
subspan->align_offset = 0;
|
|
}
|
|
subspan->span_count = (uint32_t)span_count;
|
|
}
|
|
|
|
//! Use reserved spans to fulfill a memory map request (reserve size must be
|
|
//! checked by caller)
|
|
static span_t *_rpmalloc_span_map_from_reserve(heap_t *heap,
|
|
size_t span_count) {
|
|
// Update the heap span reserve
|
|
span_t *span = heap->span_reserve;
|
|
heap->span_reserve =
|
|
(span_t *)pointer_offset(span, span_count * _memory_span_size);
|
|
heap->spans_reserved -= (uint32_t)span_count;
|
|
|
|
_rpmalloc_span_mark_as_subspan_unless_master(heap->span_reserve_master, span,
|
|
span_count);
|
|
if (span_count <= LARGE_CLASS_COUNT)
|
|
_rpmalloc_stat_inc(&heap->span_use[span_count - 1].spans_from_reserved);
|
|
|
|
return span;
|
|
}
|
|
|
|
//! Get the aligned number of spans to map in based on wanted count, configured
|
|
//! mapping granularity and the page size
|
|
static size_t _rpmalloc_span_align_count(size_t span_count) {
|
|
size_t request_count = (span_count > _memory_span_map_count)
|
|
? span_count
|
|
: _memory_span_map_count;
|
|
if ((_memory_page_size > _memory_span_size) &&
|
|
((request_count * _memory_span_size) % _memory_page_size))
|
|
request_count +=
|
|
_memory_span_map_count - (request_count % _memory_span_map_count);
|
|
return request_count;
|
|
}
|
|
|
|
//! Setup a newly mapped span
|
|
static void _rpmalloc_span_initialize(span_t *span, size_t total_span_count,
|
|
size_t span_count, size_t align_offset) {
|
|
span->total_spans = (uint32_t)total_span_count;
|
|
span->span_count = (uint32_t)span_count;
|
|
span->align_offset = (uint32_t)align_offset;
|
|
span->flags = SPAN_FLAG_MASTER;
|
|
atomic_store32(&span->remaining_spans, (int32_t)total_span_count);
|
|
}
|
|
|
|
static void _rpmalloc_span_unmap(span_t *span);
|
|
|
|
//! Map an aligned set of spans, taking configured mapping granularity and the
|
|
//! page size into account
|
|
static span_t *_rpmalloc_span_map_aligned_count(heap_t *heap,
|
|
size_t span_count) {
|
|
// If we already have some, but not enough, reserved spans, release those to
|
|
// heap cache and map a new full set of spans. Otherwise we would waste memory
|
|
// if page size > span size (huge pages)
|
|
size_t aligned_span_count = _rpmalloc_span_align_count(span_count);
|
|
size_t align_offset = 0;
|
|
span_t *span = (span_t *)_rpmalloc_mmap(
|
|
aligned_span_count * _memory_span_size, &align_offset);
|
|
if (!span)
|
|
return 0;
|
|
_rpmalloc_span_initialize(span, aligned_span_count, span_count, align_offset);
|
|
_rpmalloc_stat_inc(&_master_spans);
|
|
if (span_count <= LARGE_CLASS_COUNT)
|
|
_rpmalloc_stat_inc(&heap->span_use[span_count - 1].spans_map_calls);
|
|
if (aligned_span_count > span_count) {
|
|
span_t *reserved_spans =
|
|
(span_t *)pointer_offset(span, span_count * _memory_span_size);
|
|
size_t reserved_count = aligned_span_count - span_count;
|
|
if (heap->spans_reserved) {
|
|
_rpmalloc_span_mark_as_subspan_unless_master(
|
|
heap->span_reserve_master, heap->span_reserve, heap->spans_reserved);
|
|
_rpmalloc_heap_cache_insert(heap, heap->span_reserve);
|
|
}
|
|
if (reserved_count > _memory_heap_reserve_count) {
|
|
// If huge pages or eager spam map count, the global reserve spin lock is
|
|
// held by caller, _rpmalloc_span_map
|
|
rpmalloc_assert(atomic_load32(&_memory_global_lock) == 1,
|
|
"Global spin lock not held as expected");
|
|
size_t remain_count = reserved_count - _memory_heap_reserve_count;
|
|
reserved_count = _memory_heap_reserve_count;
|
|
span_t *remain_span = (span_t *)pointer_offset(
|
|
reserved_spans, reserved_count * _memory_span_size);
|
|
if (_memory_global_reserve) {
|
|
_rpmalloc_span_mark_as_subspan_unless_master(
|
|
_memory_global_reserve_master, _memory_global_reserve,
|
|
_memory_global_reserve_count);
|
|
_rpmalloc_span_unmap(_memory_global_reserve);
|
|
}
|
|
_rpmalloc_global_set_reserved_spans(span, remain_span, remain_count);
|
|
}
|
|
_rpmalloc_heap_set_reserved_spans(heap, span, reserved_spans,
|
|
reserved_count);
|
|
}
|
|
return span;
|
|
}
|
|
|
|
//! Map in memory pages for the given number of spans (or use previously
|
|
//! reserved pages)
|
|
static span_t *_rpmalloc_span_map(heap_t *heap, size_t span_count) {
|
|
if (span_count <= heap->spans_reserved)
|
|
return _rpmalloc_span_map_from_reserve(heap, span_count);
|
|
span_t *span = 0;
|
|
int use_global_reserve =
|
|
(_memory_page_size > _memory_span_size) ||
|
|
(_memory_span_map_count > _memory_heap_reserve_count);
|
|
if (use_global_reserve) {
|
|
// If huge pages, make sure only one thread maps more memory to avoid bloat
|
|
while (!atomic_cas32_acquire(&_memory_global_lock, 1, 0))
|
|
_rpmalloc_spin();
|
|
if (_memory_global_reserve_count >= span_count) {
|
|
size_t reserve_count =
|
|
(!heap->spans_reserved ? _memory_heap_reserve_count : span_count);
|
|
if (_memory_global_reserve_count < reserve_count)
|
|
reserve_count = _memory_global_reserve_count;
|
|
span = _rpmalloc_global_get_reserved_spans(reserve_count);
|
|
if (span) {
|
|
if (reserve_count > span_count) {
|
|
span_t *reserved_span = (span_t *)pointer_offset(
|
|
span, span_count << _memory_span_size_shift);
|
|
_rpmalloc_heap_set_reserved_spans(heap, _memory_global_reserve_master,
|
|
reserved_span,
|
|
reserve_count - span_count);
|
|
}
|
|
// Already marked as subspan in _rpmalloc_global_get_reserved_spans
|
|
span->span_count = (uint32_t)span_count;
|
|
}
|
|
}
|
|
}
|
|
if (!span)
|
|
span = _rpmalloc_span_map_aligned_count(heap, span_count);
|
|
if (use_global_reserve)
|
|
atomic_store32_release(&_memory_global_lock, 0);
|
|
return span;
|
|
}
|
|
|
|
//! Unmap memory pages for the given number of spans (or mark as unused if no
|
|
//! partial unmappings)
|
|
static void _rpmalloc_span_unmap(span_t *span) {
|
|
rpmalloc_assert((span->flags & SPAN_FLAG_MASTER) ||
|
|
(span->flags & SPAN_FLAG_SUBSPAN),
|
|
"Span flag corrupted");
|
|
rpmalloc_assert(!(span->flags & SPAN_FLAG_MASTER) ||
|
|
!(span->flags & SPAN_FLAG_SUBSPAN),
|
|
"Span flag corrupted");
|
|
|
|
int is_master = !!(span->flags & SPAN_FLAG_MASTER);
|
|
span_t *master =
|
|
is_master ? span
|
|
: ((span_t *)pointer_offset(
|
|
span, -(intptr_t)((uintptr_t)span->offset_from_master *
|
|
_memory_span_size)));
|
|
rpmalloc_assert(is_master || (span->flags & SPAN_FLAG_SUBSPAN),
|
|
"Span flag corrupted");
|
|
rpmalloc_assert(master->flags & SPAN_FLAG_MASTER, "Span flag corrupted");
|
|
|
|
size_t span_count = span->span_count;
|
|
if (!is_master) {
|
|
// Directly unmap subspans (unless huge pages, in which case we defer and
|
|
// unmap entire page range with master)
|
|
rpmalloc_assert(span->align_offset == 0, "Span align offset corrupted");
|
|
if (_memory_span_size >= _memory_page_size)
|
|
_rpmalloc_unmap(span, span_count * _memory_span_size, 0, 0);
|
|
} else {
|
|
// Special double flag to denote an unmapped master
|
|
// It must be kept in memory since span header must be used
|
|
span->flags |=
|
|
SPAN_FLAG_MASTER | SPAN_FLAG_SUBSPAN | SPAN_FLAG_UNMAPPED_MASTER;
|
|
_rpmalloc_stat_add(&_unmapped_master_spans, 1);
|
|
}
|
|
|
|
if (atomic_add32(&master->remaining_spans, -(int32_t)span_count) <= 0) {
|
|
// Everything unmapped, unmap the master span with release flag to unmap the
|
|
// entire range of the super span
|
|
rpmalloc_assert(!!(master->flags & SPAN_FLAG_MASTER) &&
|
|
!!(master->flags & SPAN_FLAG_SUBSPAN),
|
|
"Span flag corrupted");
|
|
size_t unmap_count = master->span_count;
|
|
if (_memory_span_size < _memory_page_size)
|
|
unmap_count = master->total_spans;
|
|
_rpmalloc_stat_sub(&_master_spans, 1);
|
|
_rpmalloc_stat_sub(&_unmapped_master_spans, 1);
|
|
_rpmalloc_unmap(master, unmap_count * _memory_span_size,
|
|
master->align_offset,
|
|
(size_t)master->total_spans * _memory_span_size);
|
|
}
|
|
}
|
|
|
|
//! Move the span (used for small or medium allocations) to the heap thread
|
|
//! cache
|
|
static void _rpmalloc_span_release_to_cache(heap_t *heap, span_t *span) {
|
|
rpmalloc_assert(heap == span->heap, "Span heap pointer corrupted");
|
|
rpmalloc_assert(span->size_class < SIZE_CLASS_COUNT,
|
|
"Invalid span size class");
|
|
rpmalloc_assert(span->span_count == 1, "Invalid span count");
|
|
#if ENABLE_ADAPTIVE_THREAD_CACHE || ENABLE_STATISTICS
|
|
atomic_decr32(&heap->span_use[0].current);
|
|
#endif
|
|
_rpmalloc_stat_dec(&heap->size_class_use[span->size_class].spans_current);
|
|
if (!heap->finalize) {
|
|
_rpmalloc_stat_inc(&heap->span_use[0].spans_to_cache);
|
|
_rpmalloc_stat_inc(&heap->size_class_use[span->size_class].spans_to_cache);
|
|
if (heap->size_class[span->size_class].cache)
|
|
_rpmalloc_heap_cache_insert(heap,
|
|
heap->size_class[span->size_class].cache);
|
|
heap->size_class[span->size_class].cache = span;
|
|
} else {
|
|
_rpmalloc_span_unmap(span);
|
|
}
|
|
}
|
|
|
|
//! Initialize a (partial) free list up to next system memory page, while
|
|
//! reserving the first block as allocated, returning number of blocks in list
|
|
static uint32_t free_list_partial_init(void **list, void **first_block,
|
|
void *page_start, void *block_start,
|
|
uint32_t block_count,
|
|
uint32_t block_size) {
|
|
rpmalloc_assert(block_count, "Internal failure");
|
|
*first_block = block_start;
|
|
if (block_count > 1) {
|
|
void *free_block = pointer_offset(block_start, block_size);
|
|
void *block_end =
|
|
pointer_offset(block_start, (size_t)block_size * block_count);
|
|
// If block size is less than half a memory page, bound init to next memory
|
|
// page boundary
|
|
if (block_size < (_memory_page_size >> 1)) {
|
|
void *page_end = pointer_offset(page_start, _memory_page_size);
|
|
if (page_end < block_end)
|
|
block_end = page_end;
|
|
}
|
|
*list = free_block;
|
|
block_count = 2;
|
|
void *next_block = pointer_offset(free_block, block_size);
|
|
while (next_block < block_end) {
|
|
*((void **)free_block) = next_block;
|
|
free_block = next_block;
|
|
++block_count;
|
|
next_block = pointer_offset(next_block, block_size);
|
|
}
|
|
*((void **)free_block) = 0;
|
|
} else {
|
|
*list = 0;
|
|
}
|
|
return block_count;
|
|
}
|
|
|
|
//! Initialize an unused span (from cache or mapped) to be new active span,
|
|
//! putting the initial free list in heap class free list
|
|
static void *_rpmalloc_span_initialize_new(heap_t *heap,
|
|
heap_size_class_t *heap_size_class,
|
|
span_t *span, uint32_t class_idx) {
|
|
rpmalloc_assert(span->span_count == 1, "Internal failure");
|
|
size_class_t *size_class = _memory_size_class + class_idx;
|
|
span->size_class = class_idx;
|
|
span->heap = heap;
|
|
span->flags &= ~SPAN_FLAG_ALIGNED_BLOCKS;
|
|
span->block_size = size_class->block_size;
|
|
span->block_count = size_class->block_count;
|
|
span->free_list = 0;
|
|
span->list_size = 0;
|
|
atomic_store_ptr_release(&span->free_list_deferred, 0);
|
|
|
|
// Setup free list. Only initialize one system page worth of free blocks in
|
|
// list
|
|
void *block;
|
|
span->free_list_limit =
|
|
free_list_partial_init(&heap_size_class->free_list, &block, span,
|
|
pointer_offset(span, SPAN_HEADER_SIZE),
|
|
size_class->block_count, size_class->block_size);
|
|
// Link span as partial if there remains blocks to be initialized as free
|
|
// list, or full if fully initialized
|
|
if (span->free_list_limit < span->block_count) {
|
|
_rpmalloc_span_double_link_list_add(&heap_size_class->partial_span, span);
|
|
span->used_count = span->free_list_limit;
|
|
} else {
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
_rpmalloc_span_double_link_list_add(&heap->full_span[class_idx], span);
|
|
#endif
|
|
++heap->full_span_count;
|
|
span->used_count = span->block_count;
|
|
}
|
|
return block;
|
|
}
|
|
|
|
static void _rpmalloc_span_extract_free_list_deferred(span_t *span) {
|
|
// We need acquire semantics on the CAS operation since we are interested in
|
|
// the list size Refer to _rpmalloc_deallocate_defer_small_or_medium for
|
|
// further comments on this dependency
|
|
do {
|
|
span->free_list =
|
|
atomic_exchange_ptr_acquire(&span->free_list_deferred, INVALID_POINTER);
|
|
} while (span->free_list == INVALID_POINTER);
|
|
span->used_count -= span->list_size;
|
|
span->list_size = 0;
|
|
atomic_store_ptr_release(&span->free_list_deferred, 0);
|
|
}
|
|
|
|
static int _rpmalloc_span_is_fully_utilized(span_t *span) {
|
|
rpmalloc_assert(span->free_list_limit <= span->block_count,
|
|
"Span free list corrupted");
|
|
return !span->free_list && (span->free_list_limit >= span->block_count);
|
|
}
|
|
|
|
static int _rpmalloc_span_finalize(heap_t *heap, size_t iclass, span_t *span,
|
|
span_t **list_head) {
|
|
void *free_list = heap->size_class[iclass].free_list;
|
|
span_t *class_span = (span_t *)((uintptr_t)free_list & _memory_span_mask);
|
|
if (span == class_span) {
|
|
// Adopt the heap class free list back into the span free list
|
|
void *block = span->free_list;
|
|
void *last_block = 0;
|
|
while (block) {
|
|
last_block = block;
|
|
block = *((void **)block);
|
|
}
|
|
uint32_t free_count = 0;
|
|
block = free_list;
|
|
while (block) {
|
|
++free_count;
|
|
block = *((void **)block);
|
|
}
|
|
if (last_block) {
|
|
*((void **)last_block) = free_list;
|
|
} else {
|
|
span->free_list = free_list;
|
|
}
|
|
heap->size_class[iclass].free_list = 0;
|
|
span->used_count -= free_count;
|
|
}
|
|
// If this assert triggers you have memory leaks
|
|
rpmalloc_assert(span->list_size == span->used_count, "Memory leak detected");
|
|
if (span->list_size == span->used_count) {
|
|
_rpmalloc_stat_dec(&heap->span_use[0].current);
|
|
_rpmalloc_stat_dec(&heap->size_class_use[iclass].spans_current);
|
|
// This function only used for spans in double linked lists
|
|
if (list_head)
|
|
_rpmalloc_span_double_link_list_remove(list_head, span);
|
|
_rpmalloc_span_unmap(span);
|
|
return 1;
|
|
}
|
|
return 0;
|
|
}
|
|
|
|
////////////
|
|
///
|
|
/// Global cache
|
|
///
|
|
//////
|
|
|
|
#if ENABLE_GLOBAL_CACHE
|
|
|
|
//! Finalize a global cache
|
|
static void _rpmalloc_global_cache_finalize(global_cache_t *cache) {
|
|
while (!atomic_cas32_acquire(&cache->lock, 1, 0))
|
|
_rpmalloc_spin();
|
|
|
|
for (size_t ispan = 0; ispan < cache->count; ++ispan)
|
|
_rpmalloc_span_unmap(cache->span[ispan]);
|
|
cache->count = 0;
|
|
|
|
while (cache->overflow) {
|
|
span_t *span = cache->overflow;
|
|
cache->overflow = span->next;
|
|
_rpmalloc_span_unmap(span);
|
|
}
|
|
|
|
atomic_store32_release(&cache->lock, 0);
|
|
}
|
|
|
|
static void _rpmalloc_global_cache_insert_spans(span_t **span,
|
|
size_t span_count,
|
|
size_t count) {
|
|
const size_t cache_limit =
|
|
(span_count == 1) ? GLOBAL_CACHE_MULTIPLIER * MAX_THREAD_SPAN_CACHE
|
|
: GLOBAL_CACHE_MULTIPLIER *
|
|
(MAX_THREAD_SPAN_LARGE_CACHE - (span_count >> 1));
|
|
|
|
global_cache_t *cache = &_memory_span_cache[span_count - 1];
|
|
|
|
size_t insert_count = count;
|
|
while (!atomic_cas32_acquire(&cache->lock, 1, 0))
|
|
_rpmalloc_spin();
|
|
|
|
#if ENABLE_STATISTICS
|
|
cache->insert_count += count;
|
|
#endif
|
|
if ((cache->count + insert_count) > cache_limit)
|
|
insert_count = cache_limit - cache->count;
|
|
|
|
memcpy(cache->span + cache->count, span, sizeof(span_t *) * insert_count);
|
|
cache->count += (uint32_t)insert_count;
|
|
|
|
#if ENABLE_UNLIMITED_CACHE
|
|
while (insert_count < count) {
|
|
#else
|
|
// Enable unlimited cache if huge pages, or we will leak since it is unlikely
|
|
// that an entire huge page will be unmapped, and we're unable to partially
|
|
// decommit a huge page
|
|
while ((_memory_page_size > _memory_span_size) && (insert_count < count)) {
|
|
#endif
|
|
span_t *current_span = span[insert_count++];
|
|
current_span->next = cache->overflow;
|
|
cache->overflow = current_span;
|
|
}
|
|
atomic_store32_release(&cache->lock, 0);
|
|
|
|
span_t *keep = 0;
|
|
for (size_t ispan = insert_count; ispan < count; ++ispan) {
|
|
span_t *current_span = span[ispan];
|
|
// Keep master spans that has remaining subspans to avoid dangling them
|
|
if ((current_span->flags & SPAN_FLAG_MASTER) &&
|
|
(atomic_load32(¤t_span->remaining_spans) >
|
|
(int32_t)current_span->span_count)) {
|
|
current_span->next = keep;
|
|
keep = current_span;
|
|
} else {
|
|
_rpmalloc_span_unmap(current_span);
|
|
}
|
|
}
|
|
|
|
if (keep) {
|
|
while (!atomic_cas32_acquire(&cache->lock, 1, 0))
|
|
_rpmalloc_spin();
|
|
|
|
size_t islot = 0;
|
|
while (keep) {
|
|
for (; islot < cache->count; ++islot) {
|
|
span_t *current_span = cache->span[islot];
|
|
if (!(current_span->flags & SPAN_FLAG_MASTER) ||
|
|
((current_span->flags & SPAN_FLAG_MASTER) &&
|
|
(atomic_load32(¤t_span->remaining_spans) <=
|
|
(int32_t)current_span->span_count))) {
|
|
_rpmalloc_span_unmap(current_span);
|
|
cache->span[islot] = keep;
|
|
break;
|
|
}
|
|
}
|
|
if (islot == cache->count)
|
|
break;
|
|
keep = keep->next;
|
|
}
|
|
|
|
if (keep) {
|
|
span_t *tail = keep;
|
|
while (tail->next)
|
|
tail = tail->next;
|
|
tail->next = cache->overflow;
|
|
cache->overflow = keep;
|
|
}
|
|
|
|
atomic_store32_release(&cache->lock, 0);
|
|
}
|
|
}
|
|
|
|
static size_t _rpmalloc_global_cache_extract_spans(span_t **span,
|
|
size_t span_count,
|
|
size_t count) {
|
|
global_cache_t *cache = &_memory_span_cache[span_count - 1];
|
|
|
|
size_t extract_count = 0;
|
|
while (!atomic_cas32_acquire(&cache->lock, 1, 0))
|
|
_rpmalloc_spin();
|
|
|
|
#if ENABLE_STATISTICS
|
|
cache->extract_count += count;
|
|
#endif
|
|
size_t want = count - extract_count;
|
|
if (want > cache->count)
|
|
want = cache->count;
|
|
|
|
memcpy(span + extract_count, cache->span + (cache->count - want),
|
|
sizeof(span_t *) * want);
|
|
cache->count -= (uint32_t)want;
|
|
extract_count += want;
|
|
|
|
while ((extract_count < count) && cache->overflow) {
|
|
span_t *current_span = cache->overflow;
|
|
span[extract_count++] = current_span;
|
|
cache->overflow = current_span->next;
|
|
}
|
|
|
|
#if ENABLE_ASSERTS
|
|
for (size_t ispan = 0; ispan < extract_count; ++ispan) {
|
|
rpmalloc_assert(span[ispan]->span_count == span_count,
|
|
"Global cache span count mismatch");
|
|
}
|
|
#endif
|
|
|
|
atomic_store32_release(&cache->lock, 0);
|
|
|
|
return extract_count;
|
|
}
|
|
|
|
#endif
|
|
|
|
////////////
|
|
///
|
|
/// Heap control
|
|
///
|
|
//////
|
|
|
|
static void _rpmalloc_deallocate_huge(span_t *);
|
|
|
|
//! Store the given spans as reserve in the given heap
|
|
static void _rpmalloc_heap_set_reserved_spans(heap_t *heap, span_t *master,
|
|
span_t *reserve,
|
|
size_t reserve_span_count) {
|
|
heap->span_reserve_master = master;
|
|
heap->span_reserve = reserve;
|
|
heap->spans_reserved = (uint32_t)reserve_span_count;
|
|
}
|
|
|
|
//! Adopt the deferred span cache list, optionally extracting the first single
|
|
//! span for immediate re-use
|
|
static void _rpmalloc_heap_cache_adopt_deferred(heap_t *heap,
|
|
span_t **single_span) {
|
|
span_t *span = (span_t *)((void *)atomic_exchange_ptr_acquire(
|
|
&heap->span_free_deferred, 0));
|
|
while (span) {
|
|
span_t *next_span = (span_t *)span->free_list;
|
|
rpmalloc_assert(span->heap == heap, "Span heap pointer corrupted");
|
|
if (EXPECTED(span->size_class < SIZE_CLASS_COUNT)) {
|
|
rpmalloc_assert(heap->full_span_count, "Heap span counter corrupted");
|
|
--heap->full_span_count;
|
|
_rpmalloc_stat_dec(&heap->span_use[0].spans_deferred);
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
_rpmalloc_span_double_link_list_remove(&heap->full_span[span->size_class],
|
|
span);
|
|
#endif
|
|
_rpmalloc_stat_dec(&heap->span_use[0].current);
|
|
_rpmalloc_stat_dec(&heap->size_class_use[span->size_class].spans_current);
|
|
if (single_span && !*single_span)
|
|
*single_span = span;
|
|
else
|
|
_rpmalloc_heap_cache_insert(heap, span);
|
|
} else {
|
|
if (span->size_class == SIZE_CLASS_HUGE) {
|
|
_rpmalloc_deallocate_huge(span);
|
|
} else {
|
|
rpmalloc_assert(span->size_class == SIZE_CLASS_LARGE,
|
|
"Span size class invalid");
|
|
rpmalloc_assert(heap->full_span_count, "Heap span counter corrupted");
|
|
--heap->full_span_count;
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
_rpmalloc_span_double_link_list_remove(&heap->large_huge_span, span);
|
|
#endif
|
|
uint32_t idx = span->span_count - 1;
|
|
_rpmalloc_stat_dec(&heap->span_use[idx].spans_deferred);
|
|
_rpmalloc_stat_dec(&heap->span_use[idx].current);
|
|
if (!idx && single_span && !*single_span)
|
|
*single_span = span;
|
|
else
|
|
_rpmalloc_heap_cache_insert(heap, span);
|
|
}
|
|
}
|
|
span = next_span;
|
|
}
|
|
}
|
|
|
|
static void _rpmalloc_heap_unmap(heap_t *heap) {
|
|
if (!heap->master_heap) {
|
|
if ((heap->finalize > 1) && !atomic_load32(&heap->child_count)) {
|
|
span_t *span = (span_t *)((uintptr_t)heap & _memory_span_mask);
|
|
_rpmalloc_span_unmap(span);
|
|
}
|
|
} else {
|
|
if (atomic_decr32(&heap->master_heap->child_count) == 0) {
|
|
_rpmalloc_heap_unmap(heap->master_heap);
|
|
}
|
|
}
|
|
}
|
|
|
|
static void _rpmalloc_heap_global_finalize(heap_t *heap) {
|
|
if (heap->finalize++ > 1) {
|
|
--heap->finalize;
|
|
return;
|
|
}
|
|
|
|
_rpmalloc_heap_finalize(heap);
|
|
|
|
#if ENABLE_THREAD_CACHE
|
|
for (size_t iclass = 0; iclass < LARGE_CLASS_COUNT; ++iclass) {
|
|
span_cache_t *span_cache;
|
|
if (!iclass)
|
|
span_cache = &heap->span_cache;
|
|
else
|
|
span_cache = (span_cache_t *)(heap->span_large_cache + (iclass - 1));
|
|
for (size_t ispan = 0; ispan < span_cache->count; ++ispan)
|
|
_rpmalloc_span_unmap(span_cache->span[ispan]);
|
|
span_cache->count = 0;
|
|
}
|
|
#endif
|
|
|
|
if (heap->full_span_count) {
|
|
--heap->finalize;
|
|
return;
|
|
}
|
|
|
|
for (size_t iclass = 0; iclass < SIZE_CLASS_COUNT; ++iclass) {
|
|
if (heap->size_class[iclass].free_list ||
|
|
heap->size_class[iclass].partial_span) {
|
|
--heap->finalize;
|
|
return;
|
|
}
|
|
}
|
|
// Heap is now completely free, unmap and remove from heap list
|
|
size_t list_idx = (size_t)heap->id % HEAP_ARRAY_SIZE;
|
|
heap_t *list_heap = _memory_heaps[list_idx];
|
|
if (list_heap == heap) {
|
|
_memory_heaps[list_idx] = heap->next_heap;
|
|
} else {
|
|
while (list_heap->next_heap != heap)
|
|
list_heap = list_heap->next_heap;
|
|
list_heap->next_heap = heap->next_heap;
|
|
}
|
|
|
|
_rpmalloc_heap_unmap(heap);
|
|
}
|
|
|
|
//! Insert a single span into thread heap cache, releasing to global cache if
|
|
//! overflow
|
|
static void _rpmalloc_heap_cache_insert(heap_t *heap, span_t *span) {
|
|
if (UNEXPECTED(heap->finalize != 0)) {
|
|
_rpmalloc_span_unmap(span);
|
|
_rpmalloc_heap_global_finalize(heap);
|
|
return;
|
|
}
|
|
#if ENABLE_THREAD_CACHE
|
|
size_t span_count = span->span_count;
|
|
_rpmalloc_stat_inc(&heap->span_use[span_count - 1].spans_to_cache);
|
|
if (span_count == 1) {
|
|
span_cache_t *span_cache = &heap->span_cache;
|
|
span_cache->span[span_cache->count++] = span;
|
|
if (span_cache->count == MAX_THREAD_SPAN_CACHE) {
|
|
const size_t remain_count =
|
|
MAX_THREAD_SPAN_CACHE - THREAD_SPAN_CACHE_TRANSFER;
|
|
#if ENABLE_GLOBAL_CACHE
|
|
_rpmalloc_stat_add64(&heap->thread_to_global,
|
|
THREAD_SPAN_CACHE_TRANSFER * _memory_span_size);
|
|
_rpmalloc_stat_add(&heap->span_use[span_count - 1].spans_to_global,
|
|
THREAD_SPAN_CACHE_TRANSFER);
|
|
_rpmalloc_global_cache_insert_spans(span_cache->span + remain_count,
|
|
span_count,
|
|
THREAD_SPAN_CACHE_TRANSFER);
|
|
#else
|
|
for (size_t ispan = 0; ispan < THREAD_SPAN_CACHE_TRANSFER; ++ispan)
|
|
_rpmalloc_span_unmap(span_cache->span[remain_count + ispan]);
|
|
#endif
|
|
span_cache->count = remain_count;
|
|
}
|
|
} else {
|
|
size_t cache_idx = span_count - 2;
|
|
span_large_cache_t *span_cache = heap->span_large_cache + cache_idx;
|
|
span_cache->span[span_cache->count++] = span;
|
|
const size_t cache_limit =
|
|
(MAX_THREAD_SPAN_LARGE_CACHE - (span_count >> 1));
|
|
if (span_cache->count == cache_limit) {
|
|
const size_t transfer_limit = 2 + (cache_limit >> 2);
|
|
const size_t transfer_count =
|
|
(THREAD_SPAN_LARGE_CACHE_TRANSFER <= transfer_limit
|
|
? THREAD_SPAN_LARGE_CACHE_TRANSFER
|
|
: transfer_limit);
|
|
const size_t remain_count = cache_limit - transfer_count;
|
|
#if ENABLE_GLOBAL_CACHE
|
|
_rpmalloc_stat_add64(&heap->thread_to_global,
|
|
transfer_count * span_count * _memory_span_size);
|
|
_rpmalloc_stat_add(&heap->span_use[span_count - 1].spans_to_global,
|
|
transfer_count);
|
|
_rpmalloc_global_cache_insert_spans(span_cache->span + remain_count,
|
|
span_count, transfer_count);
|
|
#else
|
|
for (size_t ispan = 0; ispan < transfer_count; ++ispan)
|
|
_rpmalloc_span_unmap(span_cache->span[remain_count + ispan]);
|
|
#endif
|
|
span_cache->count = remain_count;
|
|
}
|
|
}
|
|
#else
|
|
(void)sizeof(heap);
|
|
_rpmalloc_span_unmap(span);
|
|
#endif
|
|
}
|
|
|
|
//! Extract the given number of spans from the different cache levels
|
|
static span_t *_rpmalloc_heap_thread_cache_extract(heap_t *heap,
|
|
size_t span_count) {
|
|
span_t *span = 0;
|
|
#if ENABLE_THREAD_CACHE
|
|
span_cache_t *span_cache;
|
|
if (span_count == 1)
|
|
span_cache = &heap->span_cache;
|
|
else
|
|
span_cache = (span_cache_t *)(heap->span_large_cache + (span_count - 2));
|
|
if (span_cache->count) {
|
|
_rpmalloc_stat_inc(&heap->span_use[span_count - 1].spans_from_cache);
|
|
return span_cache->span[--span_cache->count];
|
|
}
|
|
#endif
|
|
return span;
|
|
}
|
|
|
|
static span_t *_rpmalloc_heap_thread_cache_deferred_extract(heap_t *heap,
|
|
size_t span_count) {
|
|
span_t *span = 0;
|
|
if (span_count == 1) {
|
|
_rpmalloc_heap_cache_adopt_deferred(heap, &span);
|
|
} else {
|
|
_rpmalloc_heap_cache_adopt_deferred(heap, 0);
|
|
span = _rpmalloc_heap_thread_cache_extract(heap, span_count);
|
|
}
|
|
return span;
|
|
}
|
|
|
|
static span_t *_rpmalloc_heap_reserved_extract(heap_t *heap,
|
|
size_t span_count) {
|
|
if (heap->spans_reserved >= span_count)
|
|
return _rpmalloc_span_map(heap, span_count);
|
|
return 0;
|
|
}
|
|
|
|
//! Extract a span from the global cache
|
|
static span_t *_rpmalloc_heap_global_cache_extract(heap_t *heap,
|
|
size_t span_count) {
|
|
#if ENABLE_GLOBAL_CACHE
|
|
#if ENABLE_THREAD_CACHE
|
|
span_cache_t *span_cache;
|
|
size_t wanted_count;
|
|
if (span_count == 1) {
|
|
span_cache = &heap->span_cache;
|
|
wanted_count = THREAD_SPAN_CACHE_TRANSFER;
|
|
} else {
|
|
span_cache = (span_cache_t *)(heap->span_large_cache + (span_count - 2));
|
|
wanted_count = THREAD_SPAN_LARGE_CACHE_TRANSFER;
|
|
}
|
|
span_cache->count = _rpmalloc_global_cache_extract_spans(
|
|
span_cache->span, span_count, wanted_count);
|
|
if (span_cache->count) {
|
|
_rpmalloc_stat_add64(&heap->global_to_thread,
|
|
span_count * span_cache->count * _memory_span_size);
|
|
_rpmalloc_stat_add(&heap->span_use[span_count - 1].spans_from_global,
|
|
span_cache->count);
|
|
return span_cache->span[--span_cache->count];
|
|
}
|
|
#else
|
|
span_t *span = 0;
|
|
size_t count = _rpmalloc_global_cache_extract_spans(&span, span_count, 1);
|
|
if (count) {
|
|
_rpmalloc_stat_add64(&heap->global_to_thread,
|
|
span_count * count * _memory_span_size);
|
|
_rpmalloc_stat_add(&heap->span_use[span_count - 1].spans_from_global,
|
|
count);
|
|
return span;
|
|
}
|
|
#endif
|
|
#endif
|
|
(void)sizeof(heap);
|
|
(void)sizeof(span_count);
|
|
return 0;
|
|
}
|
|
|
|
static void _rpmalloc_inc_span_statistics(heap_t *heap, size_t span_count,
|
|
uint32_t class_idx) {
|
|
(void)sizeof(heap);
|
|
(void)sizeof(span_count);
|
|
(void)sizeof(class_idx);
|
|
#if ENABLE_ADAPTIVE_THREAD_CACHE || ENABLE_STATISTICS
|
|
uint32_t idx = (uint32_t)span_count - 1;
|
|
uint32_t current_count =
|
|
(uint32_t)atomic_incr32(&heap->span_use[idx].current);
|
|
if (current_count > (uint32_t)atomic_load32(&heap->span_use[idx].high))
|
|
atomic_store32(&heap->span_use[idx].high, (int32_t)current_count);
|
|
_rpmalloc_stat_add_peak(&heap->size_class_use[class_idx].spans_current, 1,
|
|
heap->size_class_use[class_idx].spans_peak);
|
|
#endif
|
|
}
|
|
|
|
//! Get a span from one of the cache levels (thread cache, reserved, global
|
|
//! cache) or fallback to mapping more memory
|
|
static span_t *
|
|
_rpmalloc_heap_extract_new_span(heap_t *heap,
|
|
heap_size_class_t *heap_size_class,
|
|
size_t span_count, uint32_t class_idx) {
|
|
span_t *span;
|
|
#if ENABLE_THREAD_CACHE
|
|
if (heap_size_class && heap_size_class->cache) {
|
|
span = heap_size_class->cache;
|
|
heap_size_class->cache =
|
|
(heap->span_cache.count
|
|
? heap->span_cache.span[--heap->span_cache.count]
|
|
: 0);
|
|
_rpmalloc_inc_span_statistics(heap, span_count, class_idx);
|
|
return span;
|
|
}
|
|
#endif
|
|
(void)sizeof(class_idx);
|
|
// Allow 50% overhead to increase cache hits
|
|
size_t base_span_count = span_count;
|
|
size_t limit_span_count =
|
|
(span_count > 2) ? (span_count + (span_count >> 1)) : span_count;
|
|
if (limit_span_count > LARGE_CLASS_COUNT)
|
|
limit_span_count = LARGE_CLASS_COUNT;
|
|
do {
|
|
span = _rpmalloc_heap_thread_cache_extract(heap, span_count);
|
|
if (EXPECTED(span != 0)) {
|
|
_rpmalloc_stat_inc(&heap->size_class_use[class_idx].spans_from_cache);
|
|
_rpmalloc_inc_span_statistics(heap, span_count, class_idx);
|
|
return span;
|
|
}
|
|
span = _rpmalloc_heap_thread_cache_deferred_extract(heap, span_count);
|
|
if (EXPECTED(span != 0)) {
|
|
_rpmalloc_stat_inc(&heap->size_class_use[class_idx].spans_from_cache);
|
|
_rpmalloc_inc_span_statistics(heap, span_count, class_idx);
|
|
return span;
|
|
}
|
|
span = _rpmalloc_heap_global_cache_extract(heap, span_count);
|
|
if (EXPECTED(span != 0)) {
|
|
_rpmalloc_stat_inc(&heap->size_class_use[class_idx].spans_from_cache);
|
|
_rpmalloc_inc_span_statistics(heap, span_count, class_idx);
|
|
return span;
|
|
}
|
|
span = _rpmalloc_heap_reserved_extract(heap, span_count);
|
|
if (EXPECTED(span != 0)) {
|
|
_rpmalloc_stat_inc(&heap->size_class_use[class_idx].spans_from_reserved);
|
|
_rpmalloc_inc_span_statistics(heap, span_count, class_idx);
|
|
return span;
|
|
}
|
|
++span_count;
|
|
} while (span_count <= limit_span_count);
|
|
// Final fallback, map in more virtual memory
|
|
span = _rpmalloc_span_map(heap, base_span_count);
|
|
_rpmalloc_inc_span_statistics(heap, base_span_count, class_idx);
|
|
_rpmalloc_stat_inc(&heap->size_class_use[class_idx].spans_map_calls);
|
|
return span;
|
|
}
|
|
|
|
static void _rpmalloc_heap_initialize(heap_t *heap) {
|
|
_rpmalloc_memset_const(heap, 0, sizeof(heap_t));
|
|
// Get a new heap ID
|
|
heap->id = 1 + atomic_incr32(&_memory_heap_id);
|
|
|
|
// Link in heap in heap ID map
|
|
size_t list_idx = (size_t)heap->id % HEAP_ARRAY_SIZE;
|
|
heap->next_heap = _memory_heaps[list_idx];
|
|
_memory_heaps[list_idx] = heap;
|
|
}
|
|
|
|
static void _rpmalloc_heap_orphan(heap_t *heap, int first_class) {
|
|
heap->owner_thread = (uintptr_t)-1;
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
heap_t **heap_list =
|
|
(first_class ? &_memory_first_class_orphan_heaps : &_memory_orphan_heaps);
|
|
#else
|
|
(void)sizeof(first_class);
|
|
heap_t **heap_list = &_memory_orphan_heaps;
|
|
#endif
|
|
heap->next_orphan = *heap_list;
|
|
*heap_list = heap;
|
|
}
|
|
|
|
//! Allocate a new heap from newly mapped memory pages
|
|
static heap_t *_rpmalloc_heap_allocate_new(void) {
|
|
// Map in pages for a 16 heaps. If page size is greater than required size for
|
|
// this, map a page and use first part for heaps and remaining part for spans
|
|
// for allocations. Adds a lot of complexity, but saves a lot of memory on
|
|
// systems where page size > 64 spans (4MiB)
|
|
size_t heap_size = sizeof(heap_t);
|
|
size_t aligned_heap_size = 16 * ((heap_size + 15) / 16);
|
|
size_t request_heap_count = 16;
|
|
size_t heap_span_count = ((aligned_heap_size * request_heap_count) +
|
|
sizeof(span_t) + _memory_span_size - 1) /
|
|
_memory_span_size;
|
|
size_t block_size = _memory_span_size * heap_span_count;
|
|
size_t span_count = heap_span_count;
|
|
span_t *span = 0;
|
|
// If there are global reserved spans, use these first
|
|
if (_memory_global_reserve_count >= heap_span_count) {
|
|
span = _rpmalloc_global_get_reserved_spans(heap_span_count);
|
|
}
|
|
if (!span) {
|
|
if (_memory_page_size > block_size) {
|
|
span_count = _memory_page_size / _memory_span_size;
|
|
block_size = _memory_page_size;
|
|
// If using huge pages, make sure to grab enough heaps to avoid
|
|
// reallocating a huge page just to serve new heaps
|
|
size_t possible_heap_count =
|
|
(block_size - sizeof(span_t)) / aligned_heap_size;
|
|
if (possible_heap_count >= (request_heap_count * 16))
|
|
request_heap_count *= 16;
|
|
else if (possible_heap_count < request_heap_count)
|
|
request_heap_count = possible_heap_count;
|
|
heap_span_count = ((aligned_heap_size * request_heap_count) +
|
|
sizeof(span_t) + _memory_span_size - 1) /
|
|
_memory_span_size;
|
|
}
|
|
|
|
size_t align_offset = 0;
|
|
span = (span_t *)_rpmalloc_mmap(block_size, &align_offset);
|
|
if (!span)
|
|
return 0;
|
|
|
|
// Master span will contain the heaps
|
|
_rpmalloc_stat_inc(&_master_spans);
|
|
_rpmalloc_span_initialize(span, span_count, heap_span_count, align_offset);
|
|
}
|
|
|
|
size_t remain_size = _memory_span_size - sizeof(span_t);
|
|
heap_t *heap = (heap_t *)pointer_offset(span, sizeof(span_t));
|
|
_rpmalloc_heap_initialize(heap);
|
|
|
|
// Put extra heaps as orphans
|
|
size_t num_heaps = remain_size / aligned_heap_size;
|
|
if (num_heaps < request_heap_count)
|
|
num_heaps = request_heap_count;
|
|
atomic_store32(&heap->child_count, (int32_t)num_heaps - 1);
|
|
heap_t *extra_heap = (heap_t *)pointer_offset(heap, aligned_heap_size);
|
|
while (num_heaps > 1) {
|
|
_rpmalloc_heap_initialize(extra_heap);
|
|
extra_heap->master_heap = heap;
|
|
_rpmalloc_heap_orphan(extra_heap, 1);
|
|
extra_heap = (heap_t *)pointer_offset(extra_heap, aligned_heap_size);
|
|
--num_heaps;
|
|
}
|
|
|
|
if (span_count > heap_span_count) {
|
|
// Cap reserved spans
|
|
size_t remain_count = span_count - heap_span_count;
|
|
size_t reserve_count =
|
|
(remain_count > _memory_heap_reserve_count ? _memory_heap_reserve_count
|
|
: remain_count);
|
|
span_t *remain_span =
|
|
(span_t *)pointer_offset(span, heap_span_count * _memory_span_size);
|
|
_rpmalloc_heap_set_reserved_spans(heap, span, remain_span, reserve_count);
|
|
|
|
if (remain_count > reserve_count) {
|
|
// Set to global reserved spans
|
|
remain_span = (span_t *)pointer_offset(remain_span,
|
|
reserve_count * _memory_span_size);
|
|
reserve_count = remain_count - reserve_count;
|
|
_rpmalloc_global_set_reserved_spans(span, remain_span, reserve_count);
|
|
}
|
|
}
|
|
|
|
return heap;
|
|
}
|
|
|
|
static heap_t *_rpmalloc_heap_extract_orphan(heap_t **heap_list) {
|
|
heap_t *heap = *heap_list;
|
|
*heap_list = (heap ? heap->next_orphan : 0);
|
|
return heap;
|
|
}
|
|
|
|
//! Allocate a new heap, potentially reusing a previously orphaned heap
|
|
static heap_t *_rpmalloc_heap_allocate(int first_class) {
|
|
heap_t *heap = 0;
|
|
while (!atomic_cas32_acquire(&_memory_global_lock, 1, 0))
|
|
_rpmalloc_spin();
|
|
if (first_class == 0)
|
|
heap = _rpmalloc_heap_extract_orphan(&_memory_orphan_heaps);
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
if (!heap)
|
|
heap = _rpmalloc_heap_extract_orphan(&_memory_first_class_orphan_heaps);
|
|
#endif
|
|
if (!heap)
|
|
heap = _rpmalloc_heap_allocate_new();
|
|
atomic_store32_release(&_memory_global_lock, 0);
|
|
if (heap)
|
|
_rpmalloc_heap_cache_adopt_deferred(heap, 0);
|
|
return heap;
|
|
}
|
|
|
|
static void _rpmalloc_heap_release(void *heapptr, int first_class,
|
|
int release_cache) {
|
|
heap_t *heap = (heap_t *)heapptr;
|
|
if (!heap)
|
|
return;
|
|
// Release thread cache spans back to global cache
|
|
_rpmalloc_heap_cache_adopt_deferred(heap, 0);
|
|
if (release_cache || heap->finalize) {
|
|
#if ENABLE_THREAD_CACHE
|
|
for (size_t iclass = 0; iclass < LARGE_CLASS_COUNT; ++iclass) {
|
|
span_cache_t *span_cache;
|
|
if (!iclass)
|
|
span_cache = &heap->span_cache;
|
|
else
|
|
span_cache = (span_cache_t *)(heap->span_large_cache + (iclass - 1));
|
|
if (!span_cache->count)
|
|
continue;
|
|
#if ENABLE_GLOBAL_CACHE
|
|
if (heap->finalize) {
|
|
for (size_t ispan = 0; ispan < span_cache->count; ++ispan)
|
|
_rpmalloc_span_unmap(span_cache->span[ispan]);
|
|
} else {
|
|
_rpmalloc_stat_add64(&heap->thread_to_global, span_cache->count *
|
|
(iclass + 1) *
|
|
_memory_span_size);
|
|
_rpmalloc_stat_add(&heap->span_use[iclass].spans_to_global,
|
|
span_cache->count);
|
|
_rpmalloc_global_cache_insert_spans(span_cache->span, iclass + 1,
|
|
span_cache->count);
|
|
}
|
|
#else
|
|
for (size_t ispan = 0; ispan < span_cache->count; ++ispan)
|
|
_rpmalloc_span_unmap(span_cache->span[ispan]);
|
|
#endif
|
|
span_cache->count = 0;
|
|
}
|
|
#endif
|
|
}
|
|
|
|
if (get_thread_heap_raw() == heap)
|
|
set_thread_heap(0);
|
|
|
|
#if ENABLE_STATISTICS
|
|
atomic_decr32(&_memory_active_heaps);
|
|
rpmalloc_assert(atomic_load32(&_memory_active_heaps) >= 0,
|
|
"Still active heaps during finalization");
|
|
#endif
|
|
|
|
// If we are forcibly terminating with _exit the state of the
|
|
// lock atomic is unknown and it's best to just go ahead and exit
|
|
if (get_thread_id() != _rpmalloc_main_thread_id) {
|
|
while (!atomic_cas32_acquire(&_memory_global_lock, 1, 0))
|
|
_rpmalloc_spin();
|
|
}
|
|
_rpmalloc_heap_orphan(heap, first_class);
|
|
atomic_store32_release(&_memory_global_lock, 0);
|
|
}
|
|
|
|
static void _rpmalloc_heap_release_raw(void *heapptr, int release_cache) {
|
|
_rpmalloc_heap_release(heapptr, 0, release_cache);
|
|
}
|
|
|
|
static void _rpmalloc_heap_release_raw_fc(void *heapptr) {
|
|
_rpmalloc_heap_release_raw(heapptr, 1);
|
|
}
|
|
|
|
static void _rpmalloc_heap_finalize(heap_t *heap) {
|
|
if (heap->spans_reserved) {
|
|
span_t *span = _rpmalloc_span_map(heap, heap->spans_reserved);
|
|
_rpmalloc_span_unmap(span);
|
|
heap->spans_reserved = 0;
|
|
}
|
|
|
|
_rpmalloc_heap_cache_adopt_deferred(heap, 0);
|
|
|
|
for (size_t iclass = 0; iclass < SIZE_CLASS_COUNT; ++iclass) {
|
|
if (heap->size_class[iclass].cache)
|
|
_rpmalloc_span_unmap(heap->size_class[iclass].cache);
|
|
heap->size_class[iclass].cache = 0;
|
|
span_t *span = heap->size_class[iclass].partial_span;
|
|
while (span) {
|
|
span_t *next = span->next;
|
|
_rpmalloc_span_finalize(heap, iclass, span,
|
|
&heap->size_class[iclass].partial_span);
|
|
span = next;
|
|
}
|
|
// If class still has a free list it must be a full span
|
|
if (heap->size_class[iclass].free_list) {
|
|
span_t *class_span =
|
|
(span_t *)((uintptr_t)heap->size_class[iclass].free_list &
|
|
_memory_span_mask);
|
|
span_t **list = 0;
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
list = &heap->full_span[iclass];
|
|
#endif
|
|
--heap->full_span_count;
|
|
if (!_rpmalloc_span_finalize(heap, iclass, class_span, list)) {
|
|
if (list)
|
|
_rpmalloc_span_double_link_list_remove(list, class_span);
|
|
_rpmalloc_span_double_link_list_add(
|
|
&heap->size_class[iclass].partial_span, class_span);
|
|
}
|
|
}
|
|
}
|
|
|
|
#if ENABLE_THREAD_CACHE
|
|
for (size_t iclass = 0; iclass < LARGE_CLASS_COUNT; ++iclass) {
|
|
span_cache_t *span_cache;
|
|
if (!iclass)
|
|
span_cache = &heap->span_cache;
|
|
else
|
|
span_cache = (span_cache_t *)(heap->span_large_cache + (iclass - 1));
|
|
for (size_t ispan = 0; ispan < span_cache->count; ++ispan)
|
|
_rpmalloc_span_unmap(span_cache->span[ispan]);
|
|
span_cache->count = 0;
|
|
}
|
|
#endif
|
|
rpmalloc_assert(!atomic_load_ptr(&heap->span_free_deferred),
|
|
"Heaps still active during finalization");
|
|
}
|
|
|
|
////////////
|
|
///
|
|
/// Allocation entry points
|
|
///
|
|
//////
|
|
|
|
//! Pop first block from a free list
|
|
static void *free_list_pop(void **list) {
|
|
void *block = *list;
|
|
*list = *((void **)block);
|
|
return block;
|
|
}
|
|
|
|
//! Allocate a small/medium sized memory block from the given heap
|
|
static void *_rpmalloc_allocate_from_heap_fallback(
|
|
heap_t *heap, heap_size_class_t *heap_size_class, uint32_t class_idx) {
|
|
span_t *span = heap_size_class->partial_span;
|
|
rpmalloc_assume(heap != 0);
|
|
if (EXPECTED(span != 0)) {
|
|
rpmalloc_assert(span->block_count ==
|
|
_memory_size_class[span->size_class].block_count,
|
|
"Span block count corrupted");
|
|
rpmalloc_assert(!_rpmalloc_span_is_fully_utilized(span),
|
|
"Internal failure");
|
|
void *block;
|
|
if (span->free_list) {
|
|
// Span local free list is not empty, swap to size class free list
|
|
block = free_list_pop(&span->free_list);
|
|
heap_size_class->free_list = span->free_list;
|
|
span->free_list = 0;
|
|
} else {
|
|
// If the span did not fully initialize free list, link up another page
|
|
// worth of blocks
|
|
void *block_start = pointer_offset(
|
|
span, SPAN_HEADER_SIZE +
|
|
((size_t)span->free_list_limit * span->block_size));
|
|
span->free_list_limit += free_list_partial_init(
|
|
&heap_size_class->free_list, &block,
|
|
(void *)((uintptr_t)block_start & ~(_memory_page_size - 1)),
|
|
block_start, span->block_count - span->free_list_limit,
|
|
span->block_size);
|
|
}
|
|
rpmalloc_assert(span->free_list_limit <= span->block_count,
|
|
"Span block count corrupted");
|
|
span->used_count = span->free_list_limit;
|
|
|
|
// Swap in deferred free list if present
|
|
if (atomic_load_ptr(&span->free_list_deferred))
|
|
_rpmalloc_span_extract_free_list_deferred(span);
|
|
|
|
// If span is still not fully utilized keep it in partial list and early
|
|
// return block
|
|
if (!_rpmalloc_span_is_fully_utilized(span))
|
|
return block;
|
|
|
|
// The span is fully utilized, unlink from partial list and add to fully
|
|
// utilized list
|
|
_rpmalloc_span_double_link_list_pop_head(&heap_size_class->partial_span,
|
|
span);
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
_rpmalloc_span_double_link_list_add(&heap->full_span[class_idx], span);
|
|
#endif
|
|
++heap->full_span_count;
|
|
return block;
|
|
}
|
|
|
|
// Find a span in one of the cache levels
|
|
span = _rpmalloc_heap_extract_new_span(heap, heap_size_class, 1, class_idx);
|
|
if (EXPECTED(span != 0)) {
|
|
// Mark span as owned by this heap and set base data, return first block
|
|
return _rpmalloc_span_initialize_new(heap, heap_size_class, span,
|
|
class_idx);
|
|
}
|
|
|
|
return 0;
|
|
}
|
|
|
|
//! Allocate a small sized memory block from the given heap
|
|
static void *_rpmalloc_allocate_small(heap_t *heap, size_t size) {
|
|
rpmalloc_assert(heap, "No thread heap");
|
|
// Small sizes have unique size classes
|
|
const uint32_t class_idx =
|
|
(uint32_t)((size + (SMALL_GRANULARITY - 1)) >> SMALL_GRANULARITY_SHIFT);
|
|
heap_size_class_t *heap_size_class = heap->size_class + class_idx;
|
|
_rpmalloc_stat_inc_alloc(heap, class_idx);
|
|
if (EXPECTED(heap_size_class->free_list != 0))
|
|
return free_list_pop(&heap_size_class->free_list);
|
|
return _rpmalloc_allocate_from_heap_fallback(heap, heap_size_class,
|
|
class_idx);
|
|
}
|
|
|
|
//! Allocate a medium sized memory block from the given heap
|
|
static void *_rpmalloc_allocate_medium(heap_t *heap, size_t size) {
|
|
rpmalloc_assert(heap, "No thread heap");
|
|
// Calculate the size class index and do a dependent lookup of the final class
|
|
// index (in case of merged classes)
|
|
const uint32_t base_idx =
|
|
(uint32_t)(SMALL_CLASS_COUNT +
|
|
((size - (SMALL_SIZE_LIMIT + 1)) >> MEDIUM_GRANULARITY_SHIFT));
|
|
const uint32_t class_idx = _memory_size_class[base_idx].class_idx;
|
|
heap_size_class_t *heap_size_class = heap->size_class + class_idx;
|
|
_rpmalloc_stat_inc_alloc(heap, class_idx);
|
|
if (EXPECTED(heap_size_class->free_list != 0))
|
|
return free_list_pop(&heap_size_class->free_list);
|
|
return _rpmalloc_allocate_from_heap_fallback(heap, heap_size_class,
|
|
class_idx);
|
|
}
|
|
|
|
//! Allocate a large sized memory block from the given heap
|
|
static void *_rpmalloc_allocate_large(heap_t *heap, size_t size) {
|
|
rpmalloc_assert(heap, "No thread heap");
|
|
// Calculate number of needed max sized spans (including header)
|
|
// Since this function is never called if size > LARGE_SIZE_LIMIT
|
|
// the span_count is guaranteed to be <= LARGE_CLASS_COUNT
|
|
size += SPAN_HEADER_SIZE;
|
|
size_t span_count = size >> _memory_span_size_shift;
|
|
if (size & (_memory_span_size - 1))
|
|
++span_count;
|
|
|
|
// Find a span in one of the cache levels
|
|
span_t *span =
|
|
_rpmalloc_heap_extract_new_span(heap, 0, span_count, SIZE_CLASS_LARGE);
|
|
if (!span)
|
|
return span;
|
|
|
|
// Mark span as owned by this heap and set base data
|
|
rpmalloc_assert(span->span_count >= span_count, "Internal failure");
|
|
span->size_class = SIZE_CLASS_LARGE;
|
|
span->heap = heap;
|
|
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
_rpmalloc_span_double_link_list_add(&heap->large_huge_span, span);
|
|
#endif
|
|
++heap->full_span_count;
|
|
|
|
return pointer_offset(span, SPAN_HEADER_SIZE);
|
|
}
|
|
|
|
//! Allocate a huge block by mapping memory pages directly
|
|
static void *_rpmalloc_allocate_huge(heap_t *heap, size_t size) {
|
|
rpmalloc_assert(heap, "No thread heap");
|
|
_rpmalloc_heap_cache_adopt_deferred(heap, 0);
|
|
size += SPAN_HEADER_SIZE;
|
|
size_t num_pages = size >> _memory_page_size_shift;
|
|
if (size & (_memory_page_size - 1))
|
|
++num_pages;
|
|
size_t align_offset = 0;
|
|
span_t *span =
|
|
(span_t *)_rpmalloc_mmap(num_pages * _memory_page_size, &align_offset);
|
|
if (!span)
|
|
return span;
|
|
|
|
// Store page count in span_count
|
|
span->size_class = SIZE_CLASS_HUGE;
|
|
span->span_count = (uint32_t)num_pages;
|
|
span->align_offset = (uint32_t)align_offset;
|
|
span->heap = heap;
|
|
_rpmalloc_stat_add_peak(&_huge_pages_current, num_pages, _huge_pages_peak);
|
|
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
_rpmalloc_span_double_link_list_add(&heap->large_huge_span, span);
|
|
#endif
|
|
++heap->full_span_count;
|
|
|
|
return pointer_offset(span, SPAN_HEADER_SIZE);
|
|
}
|
|
|
|
//! Allocate a block of the given size
|
|
static void *_rpmalloc_allocate(heap_t *heap, size_t size) {
|
|
_rpmalloc_stat_add64(&_allocation_counter, 1);
|
|
if (EXPECTED(size <= SMALL_SIZE_LIMIT))
|
|
return _rpmalloc_allocate_small(heap, size);
|
|
else if (size <= _memory_medium_size_limit)
|
|
return _rpmalloc_allocate_medium(heap, size);
|
|
else if (size <= LARGE_SIZE_LIMIT)
|
|
return _rpmalloc_allocate_large(heap, size);
|
|
return _rpmalloc_allocate_huge(heap, size);
|
|
}
|
|
|
|
static void *_rpmalloc_aligned_allocate(heap_t *heap, size_t alignment,
|
|
size_t size) {
|
|
if (alignment <= SMALL_GRANULARITY)
|
|
return _rpmalloc_allocate(heap, size);
|
|
|
|
#if ENABLE_VALIDATE_ARGS
|
|
if ((size + alignment) < size) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
if (alignment & (alignment - 1)) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#endif
|
|
|
|
if ((alignment <= SPAN_HEADER_SIZE) &&
|
|
((size + SPAN_HEADER_SIZE) < _memory_medium_size_limit)) {
|
|
// If alignment is less or equal to span header size (which is power of
|
|
// two), and size aligned to span header size multiples is less than size +
|
|
// alignment, then use natural alignment of blocks to provide alignment
|
|
size_t multiple_size = size ? (size + (SPAN_HEADER_SIZE - 1)) &
|
|
~(uintptr_t)(SPAN_HEADER_SIZE - 1)
|
|
: SPAN_HEADER_SIZE;
|
|
rpmalloc_assert(!(multiple_size % SPAN_HEADER_SIZE),
|
|
"Failed alignment calculation");
|
|
if (multiple_size <= (size + alignment))
|
|
return _rpmalloc_allocate(heap, multiple_size);
|
|
}
|
|
|
|
void *ptr = 0;
|
|
size_t align_mask = alignment - 1;
|
|
if (alignment <= _memory_page_size) {
|
|
ptr = _rpmalloc_allocate(heap, size + alignment);
|
|
if ((uintptr_t)ptr & align_mask) {
|
|
ptr = (void *)(((uintptr_t)ptr & ~(uintptr_t)align_mask) + alignment);
|
|
// Mark as having aligned blocks
|
|
span_t *span = (span_t *)((uintptr_t)ptr & _memory_span_mask);
|
|
span->flags |= SPAN_FLAG_ALIGNED_BLOCKS;
|
|
}
|
|
return ptr;
|
|
}
|
|
|
|
// Fallback to mapping new pages for this request. Since pointers passed
|
|
// to rpfree must be able to reach the start of the span by bitmasking of
|
|
// the address with the span size, the returned aligned pointer from this
|
|
// function must be with a span size of the start of the mapped area.
|
|
// In worst case this requires us to loop and map pages until we get a
|
|
// suitable memory address. It also means we can never align to span size
|
|
// or greater, since the span header will push alignment more than one
|
|
// span size away from span start (thus causing pointer mask to give us
|
|
// an invalid span start on free)
|
|
if (alignment & align_mask) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
if (alignment >= _memory_span_size) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
|
|
size_t extra_pages = alignment / _memory_page_size;
|
|
|
|
// Since each span has a header, we will at least need one extra memory page
|
|
size_t num_pages = 1 + (size / _memory_page_size);
|
|
if (size & (_memory_page_size - 1))
|
|
++num_pages;
|
|
|
|
if (extra_pages > num_pages)
|
|
num_pages = 1 + extra_pages;
|
|
|
|
size_t original_pages = num_pages;
|
|
size_t limit_pages = (_memory_span_size / _memory_page_size) * 2;
|
|
if (limit_pages < (original_pages * 2))
|
|
limit_pages = original_pages * 2;
|
|
|
|
size_t mapped_size, align_offset;
|
|
span_t *span;
|
|
|
|
retry:
|
|
align_offset = 0;
|
|
mapped_size = num_pages * _memory_page_size;
|
|
|
|
span = (span_t *)_rpmalloc_mmap(mapped_size, &align_offset);
|
|
if (!span) {
|
|
errno = ENOMEM;
|
|
return 0;
|
|
}
|
|
ptr = pointer_offset(span, SPAN_HEADER_SIZE);
|
|
|
|
if ((uintptr_t)ptr & align_mask)
|
|
ptr = (void *)(((uintptr_t)ptr & ~(uintptr_t)align_mask) + alignment);
|
|
|
|
if (((size_t)pointer_diff(ptr, span) >= _memory_span_size) ||
|
|
(pointer_offset(ptr, size) > pointer_offset(span, mapped_size)) ||
|
|
(((uintptr_t)ptr & _memory_span_mask) != (uintptr_t)span)) {
|
|
_rpmalloc_unmap(span, mapped_size, align_offset, mapped_size);
|
|
++num_pages;
|
|
if (num_pages > limit_pages) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
goto retry;
|
|
}
|
|
|
|
// Store page count in span_count
|
|
span->size_class = SIZE_CLASS_HUGE;
|
|
span->span_count = (uint32_t)num_pages;
|
|
span->align_offset = (uint32_t)align_offset;
|
|
span->heap = heap;
|
|
_rpmalloc_stat_add_peak(&_huge_pages_current, num_pages, _huge_pages_peak);
|
|
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
_rpmalloc_span_double_link_list_add(&heap->large_huge_span, span);
|
|
#endif
|
|
++heap->full_span_count;
|
|
|
|
_rpmalloc_stat_add64(&_allocation_counter, 1);
|
|
|
|
return ptr;
|
|
}
|
|
|
|
////////////
|
|
///
|
|
/// Deallocation entry points
|
|
///
|
|
//////
|
|
|
|
//! Deallocate the given small/medium memory block in the current thread local
|
|
//! heap
|
|
static void _rpmalloc_deallocate_direct_small_or_medium(span_t *span,
|
|
void *block) {
|
|
heap_t *heap = span->heap;
|
|
rpmalloc_assert(heap->owner_thread == get_thread_id() ||
|
|
!heap->owner_thread || heap->finalize,
|
|
"Internal failure");
|
|
// Add block to free list
|
|
if (UNEXPECTED(_rpmalloc_span_is_fully_utilized(span))) {
|
|
span->used_count = span->block_count;
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
_rpmalloc_span_double_link_list_remove(&heap->full_span[span->size_class],
|
|
span);
|
|
#endif
|
|
_rpmalloc_span_double_link_list_add(
|
|
&heap->size_class[span->size_class].partial_span, span);
|
|
--heap->full_span_count;
|
|
}
|
|
*((void **)block) = span->free_list;
|
|
--span->used_count;
|
|
span->free_list = block;
|
|
if (UNEXPECTED(span->used_count == span->list_size)) {
|
|
// If there are no used blocks it is guaranteed that no other external
|
|
// thread is accessing the span
|
|
if (span->used_count) {
|
|
// Make sure we have synchronized the deferred list and list size by using
|
|
// acquire semantics and guarantee that no external thread is accessing
|
|
// span concurrently
|
|
void *free_list;
|
|
do {
|
|
free_list = atomic_exchange_ptr_acquire(&span->free_list_deferred,
|
|
INVALID_POINTER);
|
|
} while (free_list == INVALID_POINTER);
|
|
atomic_store_ptr_release(&span->free_list_deferred, free_list);
|
|
}
|
|
_rpmalloc_span_double_link_list_remove(
|
|
&heap->size_class[span->size_class].partial_span, span);
|
|
_rpmalloc_span_release_to_cache(heap, span);
|
|
}
|
|
}
|
|
|
|
static void _rpmalloc_deallocate_defer_free_span(heap_t *heap, span_t *span) {
|
|
if (span->size_class != SIZE_CLASS_HUGE)
|
|
_rpmalloc_stat_inc(&heap->span_use[span->span_count - 1].spans_deferred);
|
|
// This list does not need ABA protection, no mutable side state
|
|
do {
|
|
span->free_list = (void *)atomic_load_ptr(&heap->span_free_deferred);
|
|
} while (!atomic_cas_ptr(&heap->span_free_deferred, span, span->free_list));
|
|
}
|
|
|
|
//! Put the block in the deferred free list of the owning span
|
|
static void _rpmalloc_deallocate_defer_small_or_medium(span_t *span,
|
|
void *block) {
|
|
// The memory ordering here is a bit tricky, to avoid having to ABA protect
|
|
// the deferred free list to avoid desynchronization of list and list size
|
|
// we need to have acquire semantics on successful CAS of the pointer to
|
|
// guarantee the list_size variable validity + release semantics on pointer
|
|
// store
|
|
void *free_list;
|
|
do {
|
|
free_list =
|
|
atomic_exchange_ptr_acquire(&span->free_list_deferred, INVALID_POINTER);
|
|
} while (free_list == INVALID_POINTER);
|
|
*((void **)block) = free_list;
|
|
uint32_t free_count = ++span->list_size;
|
|
int all_deferred_free = (free_count == span->block_count);
|
|
atomic_store_ptr_release(&span->free_list_deferred, block);
|
|
if (all_deferred_free) {
|
|
// Span was completely freed by this block. Due to the INVALID_POINTER spin
|
|
// lock no other thread can reach this state simultaneously on this span.
|
|
// Safe to move to owner heap deferred cache
|
|
_rpmalloc_deallocate_defer_free_span(span->heap, span);
|
|
}
|
|
}
|
|
|
|
static void _rpmalloc_deallocate_small_or_medium(span_t *span, void *p) {
|
|
_rpmalloc_stat_inc_free(span->heap, span->size_class);
|
|
if (span->flags & SPAN_FLAG_ALIGNED_BLOCKS) {
|
|
// Realign pointer to block start
|
|
void *blocks_start = pointer_offset(span, SPAN_HEADER_SIZE);
|
|
uint32_t block_offset = (uint32_t)pointer_diff(p, blocks_start);
|
|
p = pointer_offset(p, -(int32_t)(block_offset % span->block_size));
|
|
}
|
|
// Check if block belongs to this heap or if deallocation should be deferred
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
int defer =
|
|
(span->heap->owner_thread &&
|
|
(span->heap->owner_thread != get_thread_id()) && !span->heap->finalize);
|
|
#else
|
|
int defer =
|
|
((span->heap->owner_thread != get_thread_id()) && !span->heap->finalize);
|
|
#endif
|
|
if (!defer)
|
|
_rpmalloc_deallocate_direct_small_or_medium(span, p);
|
|
else
|
|
_rpmalloc_deallocate_defer_small_or_medium(span, p);
|
|
}
|
|
|
|
//! Deallocate the given large memory block to the current heap
|
|
static void _rpmalloc_deallocate_large(span_t *span) {
|
|
rpmalloc_assert(span->size_class == SIZE_CLASS_LARGE, "Bad span size class");
|
|
rpmalloc_assert(!(span->flags & SPAN_FLAG_MASTER) ||
|
|
!(span->flags & SPAN_FLAG_SUBSPAN),
|
|
"Span flag corrupted");
|
|
rpmalloc_assert((span->flags & SPAN_FLAG_MASTER) ||
|
|
(span->flags & SPAN_FLAG_SUBSPAN),
|
|
"Span flag corrupted");
|
|
// We must always defer (unless finalizing) if from another heap since we
|
|
// cannot touch the list or counters of another heap
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
int defer =
|
|
(span->heap->owner_thread &&
|
|
(span->heap->owner_thread != get_thread_id()) && !span->heap->finalize);
|
|
#else
|
|
int defer =
|
|
((span->heap->owner_thread != get_thread_id()) && !span->heap->finalize);
|
|
#endif
|
|
if (defer) {
|
|
_rpmalloc_deallocate_defer_free_span(span->heap, span);
|
|
return;
|
|
}
|
|
rpmalloc_assert(span->heap->full_span_count, "Heap span counter corrupted");
|
|
--span->heap->full_span_count;
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
_rpmalloc_span_double_link_list_remove(&span->heap->large_huge_span, span);
|
|
#endif
|
|
#if ENABLE_ADAPTIVE_THREAD_CACHE || ENABLE_STATISTICS
|
|
// Decrease counter
|
|
size_t idx = span->span_count - 1;
|
|
atomic_decr32(&span->heap->span_use[idx].current);
|
|
#endif
|
|
heap_t *heap = span->heap;
|
|
rpmalloc_assert(heap, "No thread heap");
|
|
#if ENABLE_THREAD_CACHE
|
|
const int set_as_reserved =
|
|
((span->span_count > 1) && (heap->span_cache.count == 0) &&
|
|
!heap->finalize && !heap->spans_reserved);
|
|
#else
|
|
const int set_as_reserved =
|
|
((span->span_count > 1) && !heap->finalize && !heap->spans_reserved);
|
|
#endif
|
|
if (set_as_reserved) {
|
|
heap->span_reserve = span;
|
|
heap->spans_reserved = span->span_count;
|
|
if (span->flags & SPAN_FLAG_MASTER) {
|
|
heap->span_reserve_master = span;
|
|
} else { // SPAN_FLAG_SUBSPAN
|
|
span_t *master = (span_t *)pointer_offset(
|
|
span,
|
|
-(intptr_t)((size_t)span->offset_from_master * _memory_span_size));
|
|
heap->span_reserve_master = master;
|
|
rpmalloc_assert(master->flags & SPAN_FLAG_MASTER, "Span flag corrupted");
|
|
rpmalloc_assert(atomic_load32(&master->remaining_spans) >=
|
|
(int32_t)span->span_count,
|
|
"Master span count corrupted");
|
|
}
|
|
_rpmalloc_stat_inc(&heap->span_use[idx].spans_to_reserved);
|
|
} else {
|
|
// Insert into cache list
|
|
_rpmalloc_heap_cache_insert(heap, span);
|
|
}
|
|
}
|
|
|
|
//! Deallocate the given huge span
|
|
static void _rpmalloc_deallocate_huge(span_t *span) {
|
|
rpmalloc_assert(span->heap, "No span heap");
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
int defer =
|
|
(span->heap->owner_thread &&
|
|
(span->heap->owner_thread != get_thread_id()) && !span->heap->finalize);
|
|
#else
|
|
int defer =
|
|
((span->heap->owner_thread != get_thread_id()) && !span->heap->finalize);
|
|
#endif
|
|
if (defer) {
|
|
_rpmalloc_deallocate_defer_free_span(span->heap, span);
|
|
return;
|
|
}
|
|
rpmalloc_assert(span->heap->full_span_count, "Heap span counter corrupted");
|
|
--span->heap->full_span_count;
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
_rpmalloc_span_double_link_list_remove(&span->heap->large_huge_span, span);
|
|
#endif
|
|
|
|
// Oversized allocation, page count is stored in span_count
|
|
size_t num_pages = span->span_count;
|
|
_rpmalloc_unmap(span, num_pages * _memory_page_size, span->align_offset,
|
|
num_pages * _memory_page_size);
|
|
_rpmalloc_stat_sub(&_huge_pages_current, num_pages);
|
|
}
|
|
|
|
//! Deallocate the given block
|
|
static void _rpmalloc_deallocate(void *p) {
|
|
_rpmalloc_stat_add64(&_deallocation_counter, 1);
|
|
// Grab the span (always at start of span, using span alignment)
|
|
span_t *span = (span_t *)((uintptr_t)p & _memory_span_mask);
|
|
if (UNEXPECTED(!span))
|
|
return;
|
|
if (EXPECTED(span->size_class < SIZE_CLASS_COUNT))
|
|
_rpmalloc_deallocate_small_or_medium(span, p);
|
|
else if (span->size_class == SIZE_CLASS_LARGE)
|
|
_rpmalloc_deallocate_large(span);
|
|
else
|
|
_rpmalloc_deallocate_huge(span);
|
|
}
|
|
|
|
////////////
|
|
///
|
|
/// Reallocation entry points
|
|
///
|
|
//////
|
|
|
|
static size_t _rpmalloc_usable_size(void *p);
|
|
|
|
//! Reallocate the given block to the given size
|
|
static void *_rpmalloc_reallocate(heap_t *heap, void *p, size_t size,
|
|
size_t oldsize, unsigned int flags) {
|
|
if (p) {
|
|
// Grab the span using guaranteed span alignment
|
|
span_t *span = (span_t *)((uintptr_t)p & _memory_span_mask);
|
|
if (EXPECTED(span->size_class < SIZE_CLASS_COUNT)) {
|
|
// Small/medium sized block
|
|
rpmalloc_assert(span->span_count == 1, "Span counter corrupted");
|
|
void *blocks_start = pointer_offset(span, SPAN_HEADER_SIZE);
|
|
uint32_t block_offset = (uint32_t)pointer_diff(p, blocks_start);
|
|
uint32_t block_idx = block_offset / span->block_size;
|
|
void *block =
|
|
pointer_offset(blocks_start, (size_t)block_idx * span->block_size);
|
|
if (!oldsize)
|
|
oldsize =
|
|
(size_t)((ptrdiff_t)span->block_size - pointer_diff(p, block));
|
|
if ((size_t)span->block_size >= size) {
|
|
// Still fits in block, never mind trying to save memory, but preserve
|
|
// data if alignment changed
|
|
if ((p != block) && !(flags & RPMALLOC_NO_PRESERVE))
|
|
memmove(block, p, oldsize);
|
|
return block;
|
|
}
|
|
} else if (span->size_class == SIZE_CLASS_LARGE) {
|
|
// Large block
|
|
size_t total_size = size + SPAN_HEADER_SIZE;
|
|
size_t num_spans = total_size >> _memory_span_size_shift;
|
|
if (total_size & (_memory_span_mask - 1))
|
|
++num_spans;
|
|
size_t current_spans = span->span_count;
|
|
void *block = pointer_offset(span, SPAN_HEADER_SIZE);
|
|
if (!oldsize)
|
|
oldsize = (current_spans * _memory_span_size) -
|
|
(size_t)pointer_diff(p, block) - SPAN_HEADER_SIZE;
|
|
if ((current_spans >= num_spans) && (total_size >= (oldsize / 2))) {
|
|
// Still fits in block, never mind trying to save memory, but preserve
|
|
// data if alignment changed
|
|
if ((p != block) && !(flags & RPMALLOC_NO_PRESERVE))
|
|
memmove(block, p, oldsize);
|
|
return block;
|
|
}
|
|
} else {
|
|
// Oversized block
|
|
size_t total_size = size + SPAN_HEADER_SIZE;
|
|
size_t num_pages = total_size >> _memory_page_size_shift;
|
|
if (total_size & (_memory_page_size - 1))
|
|
++num_pages;
|
|
// Page count is stored in span_count
|
|
size_t current_pages = span->span_count;
|
|
void *block = pointer_offset(span, SPAN_HEADER_SIZE);
|
|
if (!oldsize)
|
|
oldsize = (current_pages * _memory_page_size) -
|
|
(size_t)pointer_diff(p, block) - SPAN_HEADER_SIZE;
|
|
if ((current_pages >= num_pages) && (num_pages >= (current_pages / 2))) {
|
|
// Still fits in block, never mind trying to save memory, but preserve
|
|
// data if alignment changed
|
|
if ((p != block) && !(flags & RPMALLOC_NO_PRESERVE))
|
|
memmove(block, p, oldsize);
|
|
return block;
|
|
}
|
|
}
|
|
} else {
|
|
oldsize = 0;
|
|
}
|
|
|
|
if (!!(flags & RPMALLOC_GROW_OR_FAIL))
|
|
return 0;
|
|
|
|
// Size is greater than block size, need to allocate a new block and
|
|
// deallocate the old Avoid hysteresis by overallocating if increase is small
|
|
// (below 37%)
|
|
size_t lower_bound = oldsize + (oldsize >> 2) + (oldsize >> 3);
|
|
size_t new_size =
|
|
(size > lower_bound) ? size : ((size > oldsize) ? lower_bound : size);
|
|
void *block = _rpmalloc_allocate(heap, new_size);
|
|
if (p && block) {
|
|
if (!(flags & RPMALLOC_NO_PRESERVE))
|
|
memcpy(block, p, oldsize < new_size ? oldsize : new_size);
|
|
_rpmalloc_deallocate(p);
|
|
}
|
|
|
|
return block;
|
|
}
|
|
|
|
static void *_rpmalloc_aligned_reallocate(heap_t *heap, void *ptr,
|
|
size_t alignment, size_t size,
|
|
size_t oldsize, unsigned int flags) {
|
|
if (alignment <= SMALL_GRANULARITY)
|
|
return _rpmalloc_reallocate(heap, ptr, size, oldsize, flags);
|
|
|
|
int no_alloc = !!(flags & RPMALLOC_GROW_OR_FAIL);
|
|
size_t usablesize = (ptr ? _rpmalloc_usable_size(ptr) : 0);
|
|
if ((usablesize >= size) && !((uintptr_t)ptr & (alignment - 1))) {
|
|
if (no_alloc || (size >= (usablesize / 2)))
|
|
return ptr;
|
|
}
|
|
// Aligned alloc marks span as having aligned blocks
|
|
void *block =
|
|
(!no_alloc ? _rpmalloc_aligned_allocate(heap, alignment, size) : 0);
|
|
if (EXPECTED(block != 0)) {
|
|
if (!(flags & RPMALLOC_NO_PRESERVE) && ptr) {
|
|
if (!oldsize)
|
|
oldsize = usablesize;
|
|
memcpy(block, ptr, oldsize < size ? oldsize : size);
|
|
}
|
|
_rpmalloc_deallocate(ptr);
|
|
}
|
|
return block;
|
|
}
|
|
|
|
////////////
|
|
///
|
|
/// Initialization, finalization and utility
|
|
///
|
|
//////
|
|
|
|
//! Get the usable size of the given block
|
|
static size_t _rpmalloc_usable_size(void *p) {
|
|
// Grab the span using guaranteed span alignment
|
|
span_t *span = (span_t *)((uintptr_t)p & _memory_span_mask);
|
|
if (span->size_class < SIZE_CLASS_COUNT) {
|
|
// Small/medium block
|
|
void *blocks_start = pointer_offset(span, SPAN_HEADER_SIZE);
|
|
return span->block_size -
|
|
((size_t)pointer_diff(p, blocks_start) % span->block_size);
|
|
}
|
|
if (span->size_class == SIZE_CLASS_LARGE) {
|
|
// Large block
|
|
size_t current_spans = span->span_count;
|
|
return (current_spans * _memory_span_size) - (size_t)pointer_diff(p, span);
|
|
}
|
|
// Oversized block, page count is stored in span_count
|
|
size_t current_pages = span->span_count;
|
|
return (current_pages * _memory_page_size) - (size_t)pointer_diff(p, span);
|
|
}
|
|
|
|
//! Adjust and optimize the size class properties for the given class
|
|
static void _rpmalloc_adjust_size_class(size_t iclass) {
|
|
size_t block_size = _memory_size_class[iclass].block_size;
|
|
size_t block_count = (_memory_span_size - SPAN_HEADER_SIZE) / block_size;
|
|
|
|
_memory_size_class[iclass].block_count = (uint16_t)block_count;
|
|
_memory_size_class[iclass].class_idx = (uint16_t)iclass;
|
|
|
|
// Check if previous size classes can be merged
|
|
if (iclass >= SMALL_CLASS_COUNT) {
|
|
size_t prevclass = iclass;
|
|
while (prevclass > 0) {
|
|
--prevclass;
|
|
// A class can be merged if number of pages and number of blocks are equal
|
|
if (_memory_size_class[prevclass].block_count ==
|
|
_memory_size_class[iclass].block_count)
|
|
_rpmalloc_memcpy_const(_memory_size_class + prevclass,
|
|
_memory_size_class + iclass,
|
|
sizeof(_memory_size_class[iclass]));
|
|
else
|
|
break;
|
|
}
|
|
}
|
|
}
|
|
|
|
//! Initialize the allocator and setup global data
|
|
extern inline int rpmalloc_initialize(void) {
|
|
if (_rpmalloc_initialized) {
|
|
rpmalloc_thread_initialize();
|
|
return 0;
|
|
}
|
|
return rpmalloc_initialize_config(0);
|
|
}
|
|
|
|
int rpmalloc_initialize_config(const rpmalloc_config_t *config) {
|
|
if (_rpmalloc_initialized) {
|
|
rpmalloc_thread_initialize();
|
|
return 0;
|
|
}
|
|
_rpmalloc_initialized = 1;
|
|
|
|
if (config)
|
|
memcpy(&_memory_config, config, sizeof(rpmalloc_config_t));
|
|
else
|
|
_rpmalloc_memset_const(&_memory_config, 0, sizeof(rpmalloc_config_t));
|
|
|
|
if (!_memory_config.memory_map || !_memory_config.memory_unmap) {
|
|
_memory_config.memory_map = _rpmalloc_mmap_os;
|
|
_memory_config.memory_unmap = _rpmalloc_unmap_os;
|
|
}
|
|
|
|
#if PLATFORM_WINDOWS
|
|
SYSTEM_INFO system_info;
|
|
memset(&system_info, 0, sizeof(system_info));
|
|
GetSystemInfo(&system_info);
|
|
_memory_map_granularity = system_info.dwAllocationGranularity;
|
|
#else
|
|
_memory_map_granularity = (size_t)sysconf(_SC_PAGESIZE);
|
|
#endif
|
|
|
|
#if RPMALLOC_CONFIGURABLE
|
|
_memory_page_size = _memory_config.page_size;
|
|
#else
|
|
_memory_page_size = 0;
|
|
#endif
|
|
_memory_huge_pages = 0;
|
|
if (!_memory_page_size) {
|
|
#if PLATFORM_WINDOWS
|
|
_memory_page_size = system_info.dwPageSize;
|
|
#else
|
|
_memory_page_size = _memory_map_granularity;
|
|
if (_memory_config.enable_huge_pages) {
|
|
#if defined(__linux__)
|
|
size_t huge_page_size = 0;
|
|
FILE *meminfo = fopen("/proc/meminfo", "r");
|
|
if (meminfo) {
|
|
char line[128];
|
|
while (!huge_page_size && fgets(line, sizeof(line) - 1, meminfo)) {
|
|
line[sizeof(line) - 1] = 0;
|
|
if (strstr(line, "Hugepagesize:"))
|
|
huge_page_size = (size_t)strtol(line + 13, 0, 10) * 1024;
|
|
}
|
|
fclose(meminfo);
|
|
}
|
|
if (huge_page_size) {
|
|
_memory_huge_pages = 1;
|
|
_memory_page_size = huge_page_size;
|
|
_memory_map_granularity = huge_page_size;
|
|
}
|
|
#elif defined(__FreeBSD__)
|
|
int rc;
|
|
size_t sz = sizeof(rc);
|
|
|
|
if (sysctlbyname("vm.pmap.pg_ps_enabled", &rc, &sz, NULL, 0) == 0 &&
|
|
rc == 1) {
|
|
static size_t defsize = 2 * 1024 * 1024;
|
|
int nsize = 0;
|
|
size_t sizes[4] = {0};
|
|
_memory_huge_pages = 1;
|
|
_memory_page_size = defsize;
|
|
if ((nsize = getpagesizes(sizes, 4)) >= 2) {
|
|
nsize--;
|
|
for (size_t csize = sizes[nsize]; nsize >= 0 && csize;
|
|
--nsize, csize = sizes[nsize]) {
|
|
//! Unlikely, but as a precaution..
|
|
rpmalloc_assert(!(csize & (csize - 1)) && !(csize % 1024),
|
|
"Invalid page size");
|
|
if (defsize < csize) {
|
|
_memory_page_size = csize;
|
|
break;
|
|
}
|
|
}
|
|
}
|
|
_memory_map_granularity = _memory_page_size;
|
|
}
|
|
#elif defined(__APPLE__) || defined(__NetBSD__)
|
|
_memory_huge_pages = 1;
|
|
_memory_page_size = 2 * 1024 * 1024;
|
|
_memory_map_granularity = _memory_page_size;
|
|
#endif
|
|
}
|
|
#endif
|
|
} else {
|
|
if (_memory_config.enable_huge_pages)
|
|
_memory_huge_pages = 1;
|
|
}
|
|
|
|
#if PLATFORM_WINDOWS
|
|
if (_memory_config.enable_huge_pages) {
|
|
HANDLE token = 0;
|
|
size_t large_page_minimum = GetLargePageMinimum();
|
|
if (large_page_minimum)
|
|
OpenProcessToken(GetCurrentProcess(),
|
|
TOKEN_ADJUST_PRIVILEGES | TOKEN_QUERY, &token);
|
|
if (token) {
|
|
LUID luid;
|
|
if (LookupPrivilegeValue(0, SE_LOCK_MEMORY_NAME, &luid)) {
|
|
TOKEN_PRIVILEGES token_privileges;
|
|
memset(&token_privileges, 0, sizeof(token_privileges));
|
|
token_privileges.PrivilegeCount = 1;
|
|
token_privileges.Privileges[0].Luid = luid;
|
|
token_privileges.Privileges[0].Attributes = SE_PRIVILEGE_ENABLED;
|
|
if (AdjustTokenPrivileges(token, FALSE, &token_privileges, 0, 0, 0)) {
|
|
if (GetLastError() == ERROR_SUCCESS)
|
|
_memory_huge_pages = 1;
|
|
}
|
|
}
|
|
CloseHandle(token);
|
|
}
|
|
if (_memory_huge_pages) {
|
|
if (large_page_minimum > _memory_page_size)
|
|
_memory_page_size = large_page_minimum;
|
|
if (large_page_minimum > _memory_map_granularity)
|
|
_memory_map_granularity = large_page_minimum;
|
|
}
|
|
}
|
|
#endif
|
|
|
|
size_t min_span_size = 256;
|
|
size_t max_page_size;
|
|
#if UINTPTR_MAX > 0xFFFFFFFF
|
|
max_page_size = 4096ULL * 1024ULL * 1024ULL;
|
|
#else
|
|
max_page_size = 4 * 1024 * 1024;
|
|
#endif
|
|
if (_memory_page_size < min_span_size)
|
|
_memory_page_size = min_span_size;
|
|
if (_memory_page_size > max_page_size)
|
|
_memory_page_size = max_page_size;
|
|
_memory_page_size_shift = 0;
|
|
size_t page_size_bit = _memory_page_size;
|
|
while (page_size_bit != 1) {
|
|
++_memory_page_size_shift;
|
|
page_size_bit >>= 1;
|
|
}
|
|
_memory_page_size = ((size_t)1 << _memory_page_size_shift);
|
|
|
|
#if RPMALLOC_CONFIGURABLE
|
|
if (!_memory_config.span_size) {
|
|
_memory_span_size = _memory_default_span_size;
|
|
_memory_span_size_shift = _memory_default_span_size_shift;
|
|
_memory_span_mask = _memory_default_span_mask;
|
|
} else {
|
|
size_t span_size = _memory_config.span_size;
|
|
if (span_size > (256 * 1024))
|
|
span_size = (256 * 1024);
|
|
_memory_span_size = 4096;
|
|
_memory_span_size_shift = 12;
|
|
while (_memory_span_size < span_size) {
|
|
_memory_span_size <<= 1;
|
|
++_memory_span_size_shift;
|
|
}
|
|
_memory_span_mask = ~(uintptr_t)(_memory_span_size - 1);
|
|
}
|
|
#endif
|
|
|
|
_memory_span_map_count =
|
|
(_memory_config.span_map_count ? _memory_config.span_map_count
|
|
: DEFAULT_SPAN_MAP_COUNT);
|
|
if ((_memory_span_size * _memory_span_map_count) < _memory_page_size)
|
|
_memory_span_map_count = (_memory_page_size / _memory_span_size);
|
|
if ((_memory_page_size >= _memory_span_size) &&
|
|
((_memory_span_map_count * _memory_span_size) % _memory_page_size))
|
|
_memory_span_map_count = (_memory_page_size / _memory_span_size);
|
|
_memory_heap_reserve_count = (_memory_span_map_count > DEFAULT_SPAN_MAP_COUNT)
|
|
? DEFAULT_SPAN_MAP_COUNT
|
|
: _memory_span_map_count;
|
|
|
|
_memory_config.page_size = _memory_page_size;
|
|
_memory_config.span_size = _memory_span_size;
|
|
_memory_config.span_map_count = _memory_span_map_count;
|
|
_memory_config.enable_huge_pages = _memory_huge_pages;
|
|
|
|
#if ((defined(__APPLE__) || defined(__HAIKU__)) && ENABLE_PRELOAD) || \
|
|
defined(__TINYC__)
|
|
if (pthread_key_create(&_memory_thread_heap, _rpmalloc_heap_release_raw_fc))
|
|
return -1;
|
|
#endif
|
|
#if defined(_WIN32) && (!defined(BUILD_DYNAMIC_LINK) || !BUILD_DYNAMIC_LINK)
|
|
fls_key = FlsAlloc(&_rpmalloc_thread_destructor);
|
|
#endif
|
|
|
|
// Setup all small and medium size classes
|
|
size_t iclass = 0;
|
|
_memory_size_class[iclass].block_size = SMALL_GRANULARITY;
|
|
_rpmalloc_adjust_size_class(iclass);
|
|
for (iclass = 1; iclass < SMALL_CLASS_COUNT; ++iclass) {
|
|
size_t size = iclass * SMALL_GRANULARITY;
|
|
_memory_size_class[iclass].block_size = (uint32_t)size;
|
|
_rpmalloc_adjust_size_class(iclass);
|
|
}
|
|
// At least two blocks per span, then fall back to large allocations
|
|
_memory_medium_size_limit = (_memory_span_size - SPAN_HEADER_SIZE) >> 1;
|
|
if (_memory_medium_size_limit > MEDIUM_SIZE_LIMIT)
|
|
_memory_medium_size_limit = MEDIUM_SIZE_LIMIT;
|
|
for (iclass = 0; iclass < MEDIUM_CLASS_COUNT; ++iclass) {
|
|
size_t size = SMALL_SIZE_LIMIT + ((iclass + 1) * MEDIUM_GRANULARITY);
|
|
if (size > _memory_medium_size_limit) {
|
|
_memory_medium_size_limit =
|
|
SMALL_SIZE_LIMIT + (iclass * MEDIUM_GRANULARITY);
|
|
break;
|
|
}
|
|
_memory_size_class[SMALL_CLASS_COUNT + iclass].block_size = (uint32_t)size;
|
|
_rpmalloc_adjust_size_class(SMALL_CLASS_COUNT + iclass);
|
|
}
|
|
|
|
_memory_orphan_heaps = 0;
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
_memory_first_class_orphan_heaps = 0;
|
|
#endif
|
|
#if ENABLE_STATISTICS
|
|
atomic_store32(&_memory_active_heaps, 0);
|
|
atomic_store32(&_mapped_pages, 0);
|
|
_mapped_pages_peak = 0;
|
|
atomic_store32(&_master_spans, 0);
|
|
atomic_store32(&_mapped_total, 0);
|
|
atomic_store32(&_unmapped_total, 0);
|
|
atomic_store32(&_mapped_pages_os, 0);
|
|
atomic_store32(&_huge_pages_current, 0);
|
|
_huge_pages_peak = 0;
|
|
#endif
|
|
memset(_memory_heaps, 0, sizeof(_memory_heaps));
|
|
atomic_store32_release(&_memory_global_lock, 0);
|
|
|
|
rpmalloc_linker_reference();
|
|
|
|
// Initialize this thread
|
|
rpmalloc_thread_initialize();
|
|
return 0;
|
|
}
|
|
|
|
//! Finalize the allocator
|
|
void rpmalloc_finalize(void) {
|
|
rpmalloc_thread_finalize(1);
|
|
// rpmalloc_dump_statistics(stdout);
|
|
|
|
if (_memory_global_reserve) {
|
|
atomic_add32(&_memory_global_reserve_master->remaining_spans,
|
|
-(int32_t)_memory_global_reserve_count);
|
|
_memory_global_reserve_master = 0;
|
|
_memory_global_reserve_count = 0;
|
|
_memory_global_reserve = 0;
|
|
}
|
|
atomic_store32_release(&_memory_global_lock, 0);
|
|
|
|
// Free all thread caches and fully free spans
|
|
for (size_t list_idx = 0; list_idx < HEAP_ARRAY_SIZE; ++list_idx) {
|
|
heap_t *heap = _memory_heaps[list_idx];
|
|
while (heap) {
|
|
heap_t *next_heap = heap->next_heap;
|
|
heap->finalize = 1;
|
|
_rpmalloc_heap_global_finalize(heap);
|
|
heap = next_heap;
|
|
}
|
|
}
|
|
|
|
#if ENABLE_GLOBAL_CACHE
|
|
// Free global caches
|
|
for (size_t iclass = 0; iclass < LARGE_CLASS_COUNT; ++iclass)
|
|
_rpmalloc_global_cache_finalize(&_memory_span_cache[iclass]);
|
|
#endif
|
|
|
|
#if (defined(__APPLE__) || defined(__HAIKU__)) && ENABLE_PRELOAD
|
|
pthread_key_delete(_memory_thread_heap);
|
|
#endif
|
|
#if defined(_WIN32) && (!defined(BUILD_DYNAMIC_LINK) || !BUILD_DYNAMIC_LINK)
|
|
FlsFree(fls_key);
|
|
fls_key = 0;
|
|
#endif
|
|
#if ENABLE_STATISTICS
|
|
// If you hit these asserts you probably have memory leaks (perhaps global
|
|
// scope data doing dynamic allocations) or double frees in your code
|
|
rpmalloc_assert(atomic_load32(&_mapped_pages) == 0, "Memory leak detected");
|
|
rpmalloc_assert(atomic_load32(&_mapped_pages_os) == 0,
|
|
"Memory leak detected");
|
|
#endif
|
|
|
|
_rpmalloc_initialized = 0;
|
|
}
|
|
|
|
//! Initialize thread, assign heap
|
|
extern inline void rpmalloc_thread_initialize(void) {
|
|
if (!get_thread_heap_raw()) {
|
|
heap_t *heap = _rpmalloc_heap_allocate(0);
|
|
if (heap) {
|
|
_rpmalloc_stat_inc(&_memory_active_heaps);
|
|
set_thread_heap(heap);
|
|
#if defined(_WIN32) && (!defined(BUILD_DYNAMIC_LINK) || !BUILD_DYNAMIC_LINK)
|
|
FlsSetValue(fls_key, heap);
|
|
#endif
|
|
}
|
|
}
|
|
}
|
|
|
|
//! Finalize thread, orphan heap
|
|
void rpmalloc_thread_finalize(int release_caches) {
|
|
heap_t *heap = get_thread_heap_raw();
|
|
if (heap)
|
|
_rpmalloc_heap_release_raw(heap, release_caches);
|
|
set_thread_heap(0);
|
|
#if defined(_WIN32) && (!defined(BUILD_DYNAMIC_LINK) || !BUILD_DYNAMIC_LINK)
|
|
FlsSetValue(fls_key, 0);
|
|
#endif
|
|
}
|
|
|
|
int rpmalloc_is_thread_initialized(void) {
|
|
return (get_thread_heap_raw() != 0) ? 1 : 0;
|
|
}
|
|
|
|
const rpmalloc_config_t *rpmalloc_config(void) { return &_memory_config; }
|
|
|
|
// Extern interface
|
|
|
|
extern inline RPMALLOC_ALLOCATOR void *rpmalloc(size_t size) {
|
|
#if ENABLE_VALIDATE_ARGS
|
|
if (size >= MAX_ALLOC_SIZE) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#endif
|
|
heap_t *heap = get_thread_heap();
|
|
return _rpmalloc_allocate(heap, size);
|
|
}
|
|
|
|
extern inline void rpfree(void *ptr) { _rpmalloc_deallocate(ptr); }
|
|
|
|
extern inline RPMALLOC_ALLOCATOR void *rpcalloc(size_t num, size_t size) {
|
|
size_t total;
|
|
#if ENABLE_VALIDATE_ARGS
|
|
#if PLATFORM_WINDOWS
|
|
int err = SizeTMult(num, size, &total);
|
|
if ((err != S_OK) || (total >= MAX_ALLOC_SIZE)) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#else
|
|
int err = __builtin_umull_overflow(num, size, &total);
|
|
if (err || (total >= MAX_ALLOC_SIZE)) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#endif
|
|
#else
|
|
total = num * size;
|
|
#endif
|
|
heap_t *heap = get_thread_heap();
|
|
void *block = _rpmalloc_allocate(heap, total);
|
|
if (block)
|
|
memset(block, 0, total);
|
|
return block;
|
|
}
|
|
|
|
extern inline RPMALLOC_ALLOCATOR void *rprealloc(void *ptr, size_t size) {
|
|
#if ENABLE_VALIDATE_ARGS
|
|
if (size >= MAX_ALLOC_SIZE) {
|
|
errno = EINVAL;
|
|
return ptr;
|
|
}
|
|
#endif
|
|
heap_t *heap = get_thread_heap();
|
|
return _rpmalloc_reallocate(heap, ptr, size, 0, 0);
|
|
}
|
|
|
|
extern RPMALLOC_ALLOCATOR void *rpaligned_realloc(void *ptr, size_t alignment,
|
|
size_t size, size_t oldsize,
|
|
unsigned int flags) {
|
|
#if ENABLE_VALIDATE_ARGS
|
|
if ((size + alignment < size) || (alignment > _memory_page_size)) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#endif
|
|
heap_t *heap = get_thread_heap();
|
|
return _rpmalloc_aligned_reallocate(heap, ptr, alignment, size, oldsize,
|
|
flags);
|
|
}
|
|
|
|
extern RPMALLOC_ALLOCATOR void *rpaligned_alloc(size_t alignment, size_t size) {
|
|
heap_t *heap = get_thread_heap();
|
|
return _rpmalloc_aligned_allocate(heap, alignment, size);
|
|
}
|
|
|
|
extern inline RPMALLOC_ALLOCATOR void *
|
|
rpaligned_calloc(size_t alignment, size_t num, size_t size) {
|
|
size_t total;
|
|
#if ENABLE_VALIDATE_ARGS
|
|
#if PLATFORM_WINDOWS
|
|
int err = SizeTMult(num, size, &total);
|
|
if ((err != S_OK) || (total >= MAX_ALLOC_SIZE)) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#else
|
|
int err = __builtin_umull_overflow(num, size, &total);
|
|
if (err || (total >= MAX_ALLOC_SIZE)) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#endif
|
|
#else
|
|
total = num * size;
|
|
#endif
|
|
void *block = rpaligned_alloc(alignment, total);
|
|
if (block)
|
|
memset(block, 0, total);
|
|
return block;
|
|
}
|
|
|
|
extern inline RPMALLOC_ALLOCATOR void *rpmemalign(size_t alignment,
|
|
size_t size) {
|
|
return rpaligned_alloc(alignment, size);
|
|
}
|
|
|
|
extern inline int rpposix_memalign(void **memptr, size_t alignment,
|
|
size_t size) {
|
|
if (memptr)
|
|
*memptr = rpaligned_alloc(alignment, size);
|
|
else
|
|
return EINVAL;
|
|
return *memptr ? 0 : ENOMEM;
|
|
}
|
|
|
|
extern inline size_t rpmalloc_usable_size(void *ptr) {
|
|
return (ptr ? _rpmalloc_usable_size(ptr) : 0);
|
|
}
|
|
|
|
extern inline void rpmalloc_thread_collect(void) {}
|
|
|
|
void rpmalloc_thread_statistics(rpmalloc_thread_statistics_t *stats) {
|
|
memset(stats, 0, sizeof(rpmalloc_thread_statistics_t));
|
|
heap_t *heap = get_thread_heap_raw();
|
|
if (!heap)
|
|
return;
|
|
|
|
for (size_t iclass = 0; iclass < SIZE_CLASS_COUNT; ++iclass) {
|
|
size_class_t *size_class = _memory_size_class + iclass;
|
|
span_t *span = heap->size_class[iclass].partial_span;
|
|
while (span) {
|
|
size_t free_count = span->list_size;
|
|
size_t block_count = size_class->block_count;
|
|
if (span->free_list_limit < block_count)
|
|
block_count = span->free_list_limit;
|
|
free_count += (block_count - span->used_count);
|
|
stats->sizecache += free_count * size_class->block_size;
|
|
span = span->next;
|
|
}
|
|
}
|
|
|
|
#if ENABLE_THREAD_CACHE
|
|
for (size_t iclass = 0; iclass < LARGE_CLASS_COUNT; ++iclass) {
|
|
span_cache_t *span_cache;
|
|
if (!iclass)
|
|
span_cache = &heap->span_cache;
|
|
else
|
|
span_cache = (span_cache_t *)(heap->span_large_cache + (iclass - 1));
|
|
stats->spancache += span_cache->count * (iclass + 1) * _memory_span_size;
|
|
}
|
|
#endif
|
|
|
|
span_t *deferred = (span_t *)atomic_load_ptr(&heap->span_free_deferred);
|
|
while (deferred) {
|
|
if (deferred->size_class != SIZE_CLASS_HUGE)
|
|
stats->spancache += (size_t)deferred->span_count * _memory_span_size;
|
|
deferred = (span_t *)deferred->free_list;
|
|
}
|
|
|
|
#if ENABLE_STATISTICS
|
|
stats->thread_to_global = (size_t)atomic_load64(&heap->thread_to_global);
|
|
stats->global_to_thread = (size_t)atomic_load64(&heap->global_to_thread);
|
|
|
|
for (size_t iclass = 0; iclass < LARGE_CLASS_COUNT; ++iclass) {
|
|
stats->span_use[iclass].current =
|
|
(size_t)atomic_load32(&heap->span_use[iclass].current);
|
|
stats->span_use[iclass].peak =
|
|
(size_t)atomic_load32(&heap->span_use[iclass].high);
|
|
stats->span_use[iclass].to_global =
|
|
(size_t)atomic_load32(&heap->span_use[iclass].spans_to_global);
|
|
stats->span_use[iclass].from_global =
|
|
(size_t)atomic_load32(&heap->span_use[iclass].spans_from_global);
|
|
stats->span_use[iclass].to_cache =
|
|
(size_t)atomic_load32(&heap->span_use[iclass].spans_to_cache);
|
|
stats->span_use[iclass].from_cache =
|
|
(size_t)atomic_load32(&heap->span_use[iclass].spans_from_cache);
|
|
stats->span_use[iclass].to_reserved =
|
|
(size_t)atomic_load32(&heap->span_use[iclass].spans_to_reserved);
|
|
stats->span_use[iclass].from_reserved =
|
|
(size_t)atomic_load32(&heap->span_use[iclass].spans_from_reserved);
|
|
stats->span_use[iclass].map_calls =
|
|
(size_t)atomic_load32(&heap->span_use[iclass].spans_map_calls);
|
|
}
|
|
for (size_t iclass = 0; iclass < SIZE_CLASS_COUNT; ++iclass) {
|
|
stats->size_use[iclass].alloc_current =
|
|
(size_t)atomic_load32(&heap->size_class_use[iclass].alloc_current);
|
|
stats->size_use[iclass].alloc_peak =
|
|
(size_t)heap->size_class_use[iclass].alloc_peak;
|
|
stats->size_use[iclass].alloc_total =
|
|
(size_t)atomic_load32(&heap->size_class_use[iclass].alloc_total);
|
|
stats->size_use[iclass].free_total =
|
|
(size_t)atomic_load32(&heap->size_class_use[iclass].free_total);
|
|
stats->size_use[iclass].spans_to_cache =
|
|
(size_t)atomic_load32(&heap->size_class_use[iclass].spans_to_cache);
|
|
stats->size_use[iclass].spans_from_cache =
|
|
(size_t)atomic_load32(&heap->size_class_use[iclass].spans_from_cache);
|
|
stats->size_use[iclass].spans_from_reserved = (size_t)atomic_load32(
|
|
&heap->size_class_use[iclass].spans_from_reserved);
|
|
stats->size_use[iclass].map_calls =
|
|
(size_t)atomic_load32(&heap->size_class_use[iclass].spans_map_calls);
|
|
}
|
|
#endif
|
|
}
|
|
|
|
void rpmalloc_global_statistics(rpmalloc_global_statistics_t *stats) {
|
|
memset(stats, 0, sizeof(rpmalloc_global_statistics_t));
|
|
#if ENABLE_STATISTICS
|
|
stats->mapped = (size_t)atomic_load32(&_mapped_pages) * _memory_page_size;
|
|
stats->mapped_peak = (size_t)_mapped_pages_peak * _memory_page_size;
|
|
stats->mapped_total =
|
|
(size_t)atomic_load32(&_mapped_total) * _memory_page_size;
|
|
stats->unmapped_total =
|
|
(size_t)atomic_load32(&_unmapped_total) * _memory_page_size;
|
|
stats->huge_alloc =
|
|
(size_t)atomic_load32(&_huge_pages_current) * _memory_page_size;
|
|
stats->huge_alloc_peak = (size_t)_huge_pages_peak * _memory_page_size;
|
|
#endif
|
|
#if ENABLE_GLOBAL_CACHE
|
|
for (size_t iclass = 0; iclass < LARGE_CLASS_COUNT; ++iclass) {
|
|
global_cache_t *cache = &_memory_span_cache[iclass];
|
|
while (!atomic_cas32_acquire(&cache->lock, 1, 0))
|
|
_rpmalloc_spin();
|
|
uint32_t count = cache->count;
|
|
#if ENABLE_UNLIMITED_CACHE
|
|
span_t *current_span = cache->overflow;
|
|
while (current_span) {
|
|
++count;
|
|
current_span = current_span->next;
|
|
}
|
|
#endif
|
|
atomic_store32_release(&cache->lock, 0);
|
|
stats->cached += count * (iclass + 1) * _memory_span_size;
|
|
}
|
|
#endif
|
|
}
|
|
|
|
#if ENABLE_STATISTICS
|
|
|
|
static void _memory_heap_dump_statistics(heap_t *heap, void *file) {
|
|
fprintf(file, "Heap %d stats:\n", heap->id);
|
|
fprintf(file, "Class CurAlloc PeakAlloc TotAlloc TotFree BlkSize "
|
|
"BlkCount SpansCur SpansPeak PeakAllocMiB ToCacheMiB "
|
|
"FromCacheMiB FromReserveMiB MmapCalls\n");
|
|
for (size_t iclass = 0; iclass < SIZE_CLASS_COUNT; ++iclass) {
|
|
if (!atomic_load32(&heap->size_class_use[iclass].alloc_total))
|
|
continue;
|
|
fprintf(
|
|
file,
|
|
"%3u: %10u %10u %10u %10u %8u %8u %8d %9d %13zu %11zu %12zu %14zu "
|
|
"%9u\n",
|
|
(uint32_t)iclass,
|
|
atomic_load32(&heap->size_class_use[iclass].alloc_current),
|
|
heap->size_class_use[iclass].alloc_peak,
|
|
atomic_load32(&heap->size_class_use[iclass].alloc_total),
|
|
atomic_load32(&heap->size_class_use[iclass].free_total),
|
|
_memory_size_class[iclass].block_size,
|
|
_memory_size_class[iclass].block_count,
|
|
atomic_load32(&heap->size_class_use[iclass].spans_current),
|
|
heap->size_class_use[iclass].spans_peak,
|
|
((size_t)heap->size_class_use[iclass].alloc_peak *
|
|
(size_t)_memory_size_class[iclass].block_size) /
|
|
(size_t)(1024 * 1024),
|
|
((size_t)atomic_load32(&heap->size_class_use[iclass].spans_to_cache) *
|
|
_memory_span_size) /
|
|
(size_t)(1024 * 1024),
|
|
((size_t)atomic_load32(&heap->size_class_use[iclass].spans_from_cache) *
|
|
_memory_span_size) /
|
|
(size_t)(1024 * 1024),
|
|
((size_t)atomic_load32(
|
|
&heap->size_class_use[iclass].spans_from_reserved) *
|
|
_memory_span_size) /
|
|
(size_t)(1024 * 1024),
|
|
atomic_load32(&heap->size_class_use[iclass].spans_map_calls));
|
|
}
|
|
fprintf(file, "Spans Current Peak Deferred PeakMiB Cached ToCacheMiB "
|
|
"FromCacheMiB ToReserveMiB FromReserveMiB ToGlobalMiB "
|
|
"FromGlobalMiB MmapCalls\n");
|
|
for (size_t iclass = 0; iclass < LARGE_CLASS_COUNT; ++iclass) {
|
|
if (!atomic_load32(&heap->span_use[iclass].high) &&
|
|
!atomic_load32(&heap->span_use[iclass].spans_map_calls))
|
|
continue;
|
|
fprintf(
|
|
file,
|
|
"%4u: %8d %8u %8u %8zu %7u %11zu %12zu %12zu %14zu %11zu %13zu %10u\n",
|
|
(uint32_t)(iclass + 1), atomic_load32(&heap->span_use[iclass].current),
|
|
atomic_load32(&heap->span_use[iclass].high),
|
|
atomic_load32(&heap->span_use[iclass].spans_deferred),
|
|
((size_t)atomic_load32(&heap->span_use[iclass].high) *
|
|
(size_t)_memory_span_size * (iclass + 1)) /
|
|
(size_t)(1024 * 1024),
|
|
#if ENABLE_THREAD_CACHE
|
|
(unsigned int)(!iclass ? heap->span_cache.count
|
|
: heap->span_large_cache[iclass - 1].count),
|
|
((size_t)atomic_load32(&heap->span_use[iclass].spans_to_cache) *
|
|
(iclass + 1) * _memory_span_size) /
|
|
(size_t)(1024 * 1024),
|
|
((size_t)atomic_load32(&heap->span_use[iclass].spans_from_cache) *
|
|
(iclass + 1) * _memory_span_size) /
|
|
(size_t)(1024 * 1024),
|
|
#else
|
|
0, (size_t)0, (size_t)0,
|
|
#endif
|
|
((size_t)atomic_load32(&heap->span_use[iclass].spans_to_reserved) *
|
|
(iclass + 1) * _memory_span_size) /
|
|
(size_t)(1024 * 1024),
|
|
((size_t)atomic_load32(&heap->span_use[iclass].spans_from_reserved) *
|
|
(iclass + 1) * _memory_span_size) /
|
|
(size_t)(1024 * 1024),
|
|
((size_t)atomic_load32(&heap->span_use[iclass].spans_to_global) *
|
|
(size_t)_memory_span_size * (iclass + 1)) /
|
|
(size_t)(1024 * 1024),
|
|
((size_t)atomic_load32(&heap->span_use[iclass].spans_from_global) *
|
|
(size_t)_memory_span_size * (iclass + 1)) /
|
|
(size_t)(1024 * 1024),
|
|
atomic_load32(&heap->span_use[iclass].spans_map_calls));
|
|
}
|
|
fprintf(file, "Full spans: %zu\n", heap->full_span_count);
|
|
fprintf(file, "ThreadToGlobalMiB GlobalToThreadMiB\n");
|
|
fprintf(
|
|
file, "%17zu %17zu\n",
|
|
(size_t)atomic_load64(&heap->thread_to_global) / (size_t)(1024 * 1024),
|
|
(size_t)atomic_load64(&heap->global_to_thread) / (size_t)(1024 * 1024));
|
|
}
|
|
|
|
#endif
|
|
|
|
void rpmalloc_dump_statistics(void *file) {
|
|
#if ENABLE_STATISTICS
|
|
for (size_t list_idx = 0; list_idx < HEAP_ARRAY_SIZE; ++list_idx) {
|
|
heap_t *heap = _memory_heaps[list_idx];
|
|
while (heap) {
|
|
int need_dump = 0;
|
|
for (size_t iclass = 0; !need_dump && (iclass < SIZE_CLASS_COUNT);
|
|
++iclass) {
|
|
if (!atomic_load32(&heap->size_class_use[iclass].alloc_total)) {
|
|
rpmalloc_assert(
|
|
!atomic_load32(&heap->size_class_use[iclass].free_total),
|
|
"Heap statistics counter mismatch");
|
|
rpmalloc_assert(
|
|
!atomic_load32(&heap->size_class_use[iclass].spans_map_calls),
|
|
"Heap statistics counter mismatch");
|
|
continue;
|
|
}
|
|
need_dump = 1;
|
|
}
|
|
for (size_t iclass = 0; !need_dump && (iclass < LARGE_CLASS_COUNT);
|
|
++iclass) {
|
|
if (!atomic_load32(&heap->span_use[iclass].high) &&
|
|
!atomic_load32(&heap->span_use[iclass].spans_map_calls))
|
|
continue;
|
|
need_dump = 1;
|
|
}
|
|
if (need_dump)
|
|
_memory_heap_dump_statistics(heap, file);
|
|
heap = heap->next_heap;
|
|
}
|
|
}
|
|
fprintf(file, "Global stats:\n");
|
|
size_t huge_current =
|
|
(size_t)atomic_load32(&_huge_pages_current) * _memory_page_size;
|
|
size_t huge_peak = (size_t)_huge_pages_peak * _memory_page_size;
|
|
fprintf(file, "HugeCurrentMiB HugePeakMiB\n");
|
|
fprintf(file, "%14zu %11zu\n", huge_current / (size_t)(1024 * 1024),
|
|
huge_peak / (size_t)(1024 * 1024));
|
|
|
|
#if ENABLE_GLOBAL_CACHE
|
|
fprintf(file, "GlobalCacheMiB\n");
|
|
for (size_t iclass = 0; iclass < LARGE_CLASS_COUNT; ++iclass) {
|
|
global_cache_t *cache = _memory_span_cache + iclass;
|
|
size_t global_cache = (size_t)cache->count * iclass * _memory_span_size;
|
|
|
|
size_t global_overflow_cache = 0;
|
|
span_t *span = cache->overflow;
|
|
while (span) {
|
|
global_overflow_cache += iclass * _memory_span_size;
|
|
span = span->next;
|
|
}
|
|
if (global_cache || global_overflow_cache || cache->insert_count ||
|
|
cache->extract_count)
|
|
fprintf(file,
|
|
"%4zu: %8zuMiB (%8zuMiB overflow) %14zu insert %14zu extract\n",
|
|
iclass + 1, global_cache / (size_t)(1024 * 1024),
|
|
global_overflow_cache / (size_t)(1024 * 1024),
|
|
cache->insert_count, cache->extract_count);
|
|
}
|
|
#endif
|
|
|
|
size_t mapped = (size_t)atomic_load32(&_mapped_pages) * _memory_page_size;
|
|
size_t mapped_os =
|
|
(size_t)atomic_load32(&_mapped_pages_os) * _memory_page_size;
|
|
size_t mapped_peak = (size_t)_mapped_pages_peak * _memory_page_size;
|
|
size_t mapped_total =
|
|
(size_t)atomic_load32(&_mapped_total) * _memory_page_size;
|
|
size_t unmapped_total =
|
|
(size_t)atomic_load32(&_unmapped_total) * _memory_page_size;
|
|
fprintf(
|
|
file,
|
|
"MappedMiB MappedOSMiB MappedPeakMiB MappedTotalMiB UnmappedTotalMiB\n");
|
|
fprintf(file, "%9zu %11zu %13zu %14zu %16zu\n",
|
|
mapped / (size_t)(1024 * 1024), mapped_os / (size_t)(1024 * 1024),
|
|
mapped_peak / (size_t)(1024 * 1024),
|
|
mapped_total / (size_t)(1024 * 1024),
|
|
unmapped_total / (size_t)(1024 * 1024));
|
|
|
|
fprintf(file, "\n");
|
|
#if 0
|
|
int64_t allocated = atomic_load64(&_allocation_counter);
|
|
int64_t deallocated = atomic_load64(&_deallocation_counter);
|
|
fprintf(file, "Allocation count: %lli\n", allocated);
|
|
fprintf(file, "Deallocation count: %lli\n", deallocated);
|
|
fprintf(file, "Current allocations: %lli\n", (allocated - deallocated));
|
|
fprintf(file, "Master spans: %d\n", atomic_load32(&_master_spans));
|
|
fprintf(file, "Dangling master spans: %d\n", atomic_load32(&_unmapped_master_spans));
|
|
#endif
|
|
#endif
|
|
(void)sizeof(file);
|
|
}
|
|
|
|
#if RPMALLOC_FIRST_CLASS_HEAPS
|
|
|
|
extern inline rpmalloc_heap_t *rpmalloc_heap_acquire(void) {
|
|
// Must be a pristine heap from newly mapped memory pages, or else memory
|
|
// blocks could already be allocated from the heap which would (wrongly) be
|
|
// released when heap is cleared with rpmalloc_heap_free_all(). Also heaps
|
|
// guaranteed to be pristine from the dedicated orphan list can be used.
|
|
heap_t *heap = _rpmalloc_heap_allocate(1);
|
|
rpmalloc_assume(heap != NULL);
|
|
heap->owner_thread = 0;
|
|
_rpmalloc_stat_inc(&_memory_active_heaps);
|
|
return heap;
|
|
}
|
|
|
|
extern inline void rpmalloc_heap_release(rpmalloc_heap_t *heap) {
|
|
if (heap)
|
|
_rpmalloc_heap_release(heap, 1, 1);
|
|
}
|
|
|
|
extern inline RPMALLOC_ALLOCATOR void *
|
|
rpmalloc_heap_alloc(rpmalloc_heap_t *heap, size_t size) {
|
|
#if ENABLE_VALIDATE_ARGS
|
|
if (size >= MAX_ALLOC_SIZE) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#endif
|
|
return _rpmalloc_allocate(heap, size);
|
|
}
|
|
|
|
extern inline RPMALLOC_ALLOCATOR void *
|
|
rpmalloc_heap_aligned_alloc(rpmalloc_heap_t *heap, size_t alignment,
|
|
size_t size) {
|
|
#if ENABLE_VALIDATE_ARGS
|
|
if (size >= MAX_ALLOC_SIZE) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#endif
|
|
return _rpmalloc_aligned_allocate(heap, alignment, size);
|
|
}
|
|
|
|
extern inline RPMALLOC_ALLOCATOR void *
|
|
rpmalloc_heap_calloc(rpmalloc_heap_t *heap, size_t num, size_t size) {
|
|
return rpmalloc_heap_aligned_calloc(heap, 0, num, size);
|
|
}
|
|
|
|
extern inline RPMALLOC_ALLOCATOR void *
|
|
rpmalloc_heap_aligned_calloc(rpmalloc_heap_t *heap, size_t alignment,
|
|
size_t num, size_t size) {
|
|
size_t total;
|
|
#if ENABLE_VALIDATE_ARGS
|
|
#if PLATFORM_WINDOWS
|
|
int err = SizeTMult(num, size, &total);
|
|
if ((err != S_OK) || (total >= MAX_ALLOC_SIZE)) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#else
|
|
int err = __builtin_umull_overflow(num, size, &total);
|
|
if (err || (total >= MAX_ALLOC_SIZE)) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#endif
|
|
#else
|
|
total = num * size;
|
|
#endif
|
|
void *block = _rpmalloc_aligned_allocate(heap, alignment, total);
|
|
if (block)
|
|
memset(block, 0, total);
|
|
return block;
|
|
}
|
|
|
|
extern inline RPMALLOC_ALLOCATOR void *
|
|
rpmalloc_heap_realloc(rpmalloc_heap_t *heap, void *ptr, size_t size,
|
|
unsigned int flags) {
|
|
#if ENABLE_VALIDATE_ARGS
|
|
if (size >= MAX_ALLOC_SIZE) {
|
|
errno = EINVAL;
|
|
return ptr;
|
|
}
|
|
#endif
|
|
return _rpmalloc_reallocate(heap, ptr, size, 0, flags);
|
|
}
|
|
|
|
extern inline RPMALLOC_ALLOCATOR void *
|
|
rpmalloc_heap_aligned_realloc(rpmalloc_heap_t *heap, void *ptr,
|
|
size_t alignment, size_t size,
|
|
unsigned int flags) {
|
|
#if ENABLE_VALIDATE_ARGS
|
|
if ((size + alignment < size) || (alignment > _memory_page_size)) {
|
|
errno = EINVAL;
|
|
return 0;
|
|
}
|
|
#endif
|
|
return _rpmalloc_aligned_reallocate(heap, ptr, alignment, size, 0, flags);
|
|
}
|
|
|
|
extern inline void rpmalloc_heap_free(rpmalloc_heap_t *heap, void *ptr) {
|
|
(void)sizeof(heap);
|
|
_rpmalloc_deallocate(ptr);
|
|
}
|
|
|
|
extern inline void rpmalloc_heap_free_all(rpmalloc_heap_t *heap) {
|
|
span_t *span;
|
|
span_t *next_span;
|
|
|
|
_rpmalloc_heap_cache_adopt_deferred(heap, 0);
|
|
|
|
for (size_t iclass = 0; iclass < SIZE_CLASS_COUNT; ++iclass) {
|
|
span = heap->size_class[iclass].partial_span;
|
|
while (span) {
|
|
next_span = span->next;
|
|
_rpmalloc_heap_cache_insert(heap, span);
|
|
span = next_span;
|
|
}
|
|
heap->size_class[iclass].partial_span = 0;
|
|
span = heap->full_span[iclass];
|
|
while (span) {
|
|
next_span = span->next;
|
|
_rpmalloc_heap_cache_insert(heap, span);
|
|
span = next_span;
|
|
}
|
|
|
|
span = heap->size_class[iclass].cache;
|
|
if (span)
|
|
_rpmalloc_heap_cache_insert(heap, span);
|
|
heap->size_class[iclass].cache = 0;
|
|
}
|
|
memset(heap->size_class, 0, sizeof(heap->size_class));
|
|
memset(heap->full_span, 0, sizeof(heap->full_span));
|
|
|
|
span = heap->large_huge_span;
|
|
while (span) {
|
|
next_span = span->next;
|
|
if (UNEXPECTED(span->size_class == SIZE_CLASS_HUGE))
|
|
_rpmalloc_deallocate_huge(span);
|
|
else
|
|
_rpmalloc_heap_cache_insert(heap, span);
|
|
span = next_span;
|
|
}
|
|
heap->large_huge_span = 0;
|
|
heap->full_span_count = 0;
|
|
|
|
#if ENABLE_THREAD_CACHE
|
|
for (size_t iclass = 0; iclass < LARGE_CLASS_COUNT; ++iclass) {
|
|
span_cache_t *span_cache;
|
|
if (!iclass)
|
|
span_cache = &heap->span_cache;
|
|
else
|
|
span_cache = (span_cache_t *)(heap->span_large_cache + (iclass - 1));
|
|
if (!span_cache->count)
|
|
continue;
|
|
#if ENABLE_GLOBAL_CACHE
|
|
_rpmalloc_stat_add64(&heap->thread_to_global,
|
|
span_cache->count * (iclass + 1) * _memory_span_size);
|
|
_rpmalloc_stat_add(&heap->span_use[iclass].spans_to_global,
|
|
span_cache->count);
|
|
_rpmalloc_global_cache_insert_spans(span_cache->span, iclass + 1,
|
|
span_cache->count);
|
|
#else
|
|
for (size_t ispan = 0; ispan < span_cache->count; ++ispan)
|
|
_rpmalloc_span_unmap(span_cache->span[ispan]);
|
|
#endif
|
|
span_cache->count = 0;
|
|
}
|
|
#endif
|
|
|
|
#if ENABLE_STATISTICS
|
|
for (size_t iclass = 0; iclass < SIZE_CLASS_COUNT; ++iclass) {
|
|
atomic_store32(&heap->size_class_use[iclass].alloc_current, 0);
|
|
atomic_store32(&heap->size_class_use[iclass].spans_current, 0);
|
|
}
|
|
for (size_t iclass = 0; iclass < LARGE_CLASS_COUNT; ++iclass) {
|
|
atomic_store32(&heap->span_use[iclass].current, 0);
|
|
}
|
|
#endif
|
|
}
|
|
|
|
extern inline void rpmalloc_heap_thread_set_current(rpmalloc_heap_t *heap) {
|
|
heap_t *prev_heap = get_thread_heap_raw();
|
|
if (prev_heap != heap) {
|
|
set_thread_heap(heap);
|
|
if (prev_heap)
|
|
rpmalloc_heap_release(prev_heap);
|
|
}
|
|
}
|
|
|
|
extern inline rpmalloc_heap_t *rpmalloc_get_heap_for_ptr(void *ptr) {
|
|
// Grab the span, and then the heap from the span
|
|
span_t *span = (span_t *)((uintptr_t)ptr & _memory_span_mask);
|
|
if (span) {
|
|
return span->heap;
|
|
}
|
|
return 0;
|
|
}
|
|
|
|
#endif
|
|
|
|
#if ENABLE_PRELOAD || ENABLE_OVERRIDE
|
|
|
|
#include "malloc.c"
|
|
|
|
#endif
|
|
|
|
void rpmalloc_linker_reference(void) { (void)sizeof(_rpmalloc_initialized); }
|